tidyr によるデータフレームの操作
概要
講義: 30 分
演習: 15 分質問
データフレームのフォーマットを変更するにはどのようにすればよいですか?
目標
「横長」と「縦長」のデータ形式を理解し、
tidyrを使用して、その変換が出来るようになりましょう。
研究者には「横長」データを「縦長」データに(又はその逆を)したいと 思うことがよくあります。 「縦長」形式とは:
- 各列が変数
- 各行が観測値
「縦長」形式では、普通、観測値は1列で、残りの列はIDの変数になります。
「横長」形式は、それぞれの行には、場所/主題/患者があり、同じようなデータ型の 複数の観測変数があります。 時間を変えて繰り返し観測した値や、 複数の観測変数(又は、その両方)が、これに該当します。 データ入力がより単純と感じたり、「縦長」形式の方が良いという アプリケーションもあるでしょうが、「R」の関数の多くは、 「縦長」形式データを前提として作られています。ここでは、 元々の形式に関係なくデータを効率的に変換する方法を学びましょう。
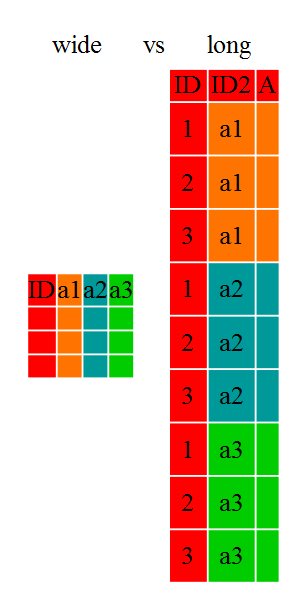
これらのデータ形式は、主に読みやすさに影響します。画面の形状上、より多くのデータが見られる 横長形式を、人間は直感的に選好しやすいところですが、縦長形式の方が機械が読みやすく、 データベースの形式に近いのです。データフレームにある ID 変数は、データベースにあるフィールドの ようなものであり、観測された変数はデータべースの値のようなものです。
手始めに
まず、パッケージをインストールしましょう、もしまだやっていなければですが (おそらく、前の dplyr のレッスンで、インストールしているかと思います):
#install.packages("tidyr")
#install.packages("dplyr")
パーッケージをロードしましょう。
library("tidyr")
library("dplyr")
始めに、そもそもの gapminder データフレームのデータ構造を見てみましょう:
str(gapminder)
'data.frame':\t1704 obs. of 6 variables:
$ country : chr "Afghanistan" "Afghanistan" "Afghanistan" "Afghanistan" ...
$ year : int 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 ...
$ pop : num 8425333 9240934 10267083 11537966 13079460 ...
$ continent: chr "Asia" "Asia" "Asia" "Asia" ...
$ lifeExp : num 28.8 30.3 32 34 36.1 ...
$ gdpPercap: num 779 821 853 836 740 ...
チャレンジ1
gapminder は、横長のみ、縦長のみ、又はその中間の形式でしょうか。
チャレンジ1の解答
元々の gapminder data.frame は、中間の形式です。 複数の観測変数(
pop,lifeExp,gdpPercap)があるため、 縦長のみのデータとは言えません。
ときどき gapminder データセットのように、観測データが複数の型の場合があります。
これは「縦長」と「横長」のデータ形式の中間のようなものです。
3つの「ID variables」(continent, country, year)と、3つの「観測変数」
(pop,lifeExp,gdpPercap)がありますね。3つの観測変数が、全ての違う
単位であり、全ての変数が1列になってはいませんが、個人的には、自分のデータを、
この中間形式にしたいと思うことが多いです。このデータフレームをより縦に広げたい
(つまり、4つの ID 変数と1観測変数にしたい)というときに使える操作は、
ほとんどありません。
一方で、R の関数の多くは、ベクトルに基づいているものがほとんどであり、ふつうは
単位が異なる値に、数理的演算をすることは避けたいと思うでしょう。
例えば、縦長の形式のみを使って、人口、平均余命及びGDPの値の全てを使って、
ひとつ平均値を出しても、意味がないでしょう。3つの比較できない単位の値の平均と
なるのですから。解決方法は、データをまずグループ化(dplyr のレッスンを参照)するか、
データフレームの形式を変えることでしょう。 注: Rのプロット関数の中には、
横長形式のデータの方がよいものもあります。
gather() を使って、横長から縦長形式へ
ここまでは、元々の gapminder データセットの形式を整えてきましたが、 ‘本物の’ データ(つまり、研究データ)が、ちゃんと整理されていることは ほとんどないでしょう。ここで、gapminderデータセットの横長形式から、始めてみましょう。
横長バージョンの gapminder データを ここからダウンロードしましょう。 そしてフォルダーに保存します。
データファイルをロードして見てみましょう。 注:大陸と国の列は、因子型にはしたくありません。
そこで、そうならないように、read.csv()に stringsAsFactors 引数を使いましょう。
gap_wide <- read.csv("data/gapminder_wide.csv", stringsAsFactors = FALSE)
str(gap_wide)
'data.frame':\t142 obs. of 38 variables:
$ continent : chr "Africa" "Africa" "Africa" "Africa" ...
$ country : chr "Algeria" "Angola" "Benin" "Botswana" ...
$ gdpPercap_1952: num 2449 3521 1063 851 543 ...
$ gdpPercap_1957: num 3014 3828 960 918 617 ...
$ gdpPercap_1962: num 2551 4269 949 984 723 ...
$ gdpPercap_1967: num 3247 5523 1036 1215 795 ...
$ gdpPercap_1972: num 4183 5473 1086 2264 855 ...
$ gdpPercap_1977: num 4910 3009 1029 3215 743 ...
$ gdpPercap_1982: num 5745 2757 1278 4551 807 ...
$ gdpPercap_1987: num 5681 2430 1226 6206 912 ...
$ gdpPercap_1992: num 5023 2628 1191 7954 932 ...
$ gdpPercap_1997: num 4797 2277 1233 8647 946 ...
$ gdpPercap_2002: num 5288 2773 1373 11004 1038 ...
$ gdpPercap_2007: num 6223 4797 1441 12570 1217 ...
$ lifeExp_1952 : num 43.1 30 38.2 47.6 32 ...
$ lifeExp_1957 : num 45.7 32 40.4 49.6 34.9 ...
$ lifeExp_1962 : num 48.3 34 42.6 51.5 37.8 ...
$ lifeExp_1967 : num 51.4 36 44.9 53.3 40.7 ...
$ lifeExp_1972 : num 54.5 37.9 47 56 43.6 ...
$ lifeExp_1977 : num 58 39.5 49.2 59.3 46.1 ...
$ lifeExp_1982 : num 61.4 39.9 50.9 61.5 48.1 ...
$ lifeExp_1987 : num 65.8 39.9 52.3 63.6 49.6 ...
$ lifeExp_1992 : num 67.7 40.6 53.9 62.7 50.3 ...
$ lifeExp_1997 : num 69.2 41 54.8 52.6 50.3 ...
$ lifeExp_2002 : num 71 41 54.4 46.6 50.6 ...
$ lifeExp_2007 : num 72.3 42.7 56.7 50.7 52.3 ...
$ pop_1952 : num 9279525 4232095 1738315 442308 4469979 ...
$ pop_1957 : num 10270856 4561361 1925173 474639 4713416 ...
$ pop_1962 : num 11000948 4826015 2151895 512764 4919632 ...
$ pop_1967 : num 12760499 5247469 2427334 553541 5127935 ...
$ pop_1972 : num 14760787 5894858 2761407 619351 5433886 ...
$ pop_1977 : num 17152804 6162675 3168267 781472 5889574 ...
$ pop_1982 : num 20033753 7016384 3641603 970347 6634596 ...
$ pop_1987 : num 23254956 7874230 4243788 1151184 7586551 ...
$ pop_1992 : num 26298373 8735988 4981671 1342614 8878303 ...
$ pop_1997 : num 29072015 9875024 6066080 1536536 10352843 ...
$ pop_2002 : int 31287142 10866106 7026113 1630347 12251209 7021078 15929988 4048013 8835739 614382 ...
$ pop_2007 : int 33333216 12420476 8078314 1639131 14326203 8390505 17696293 4369038 10238807 710960 ...

我々の目指す中間形式のデータに向かう最初のステップは、
横長から縦長形式への変換です。 tidyr 関数の gather() を使えば、
観測変数をひとつの変数に ‘集める(gather)’ することができます。
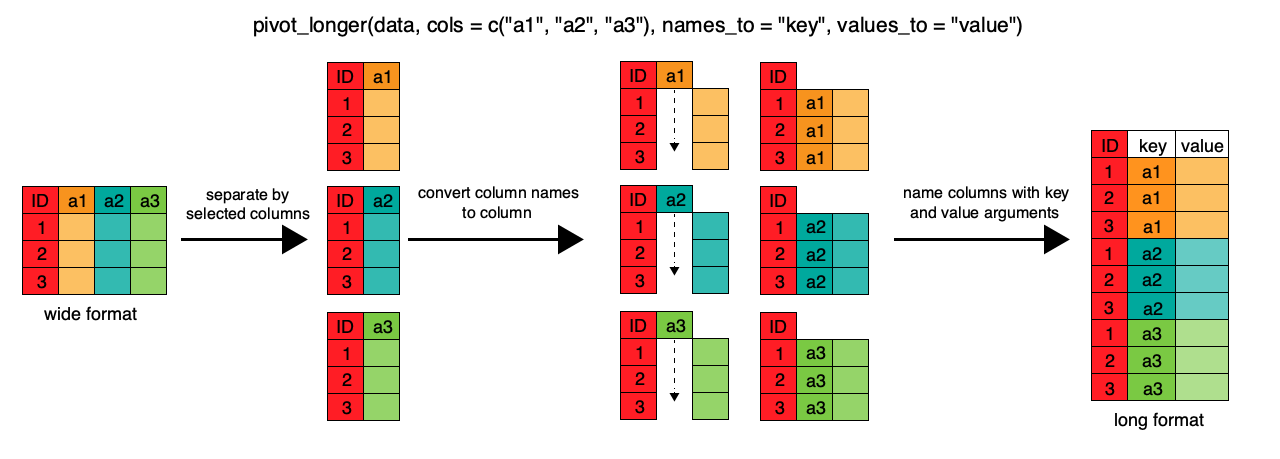
gap_long <- gap_wide %>%
gather(obstype_year, obs_values, starts_with('pop'),
starts_with('lifeExp'), starts_with('gdpPercap'))
str(gap_long)
'data.frame':\t5112 obs. of 4 variables:
$ continent : chr "Africa" "Africa" "Africa" "Africa" ...
$ country : chr "Algeria" "Angola" "Benin" "Botswana" ...
$ obstype_year: chr "pop_1952" "pop_1952" "pop_1952" "pop_1952" ...
$ obs_values : num 9279525 4232095 1738315 442308 4469979 ...
ここでは、以前 dplyr のレッスンの中で行ったようなパイプの書き方を使いました。 実は、tidyr と dplyr 関数は互換性があり、パイプで繋ぐことで、一緒に使うことが できるのです。
始めに、新しいID変数(obstype_year)のための新しい列、新しくまとめた
観測変数(obs_value)、及び古い観測変数を gather() の中で名付けましょう。
全ての観測変数をタイプすることもできますが、 select() 関数(dplyr レッスン参照)
でしたように、引数 starts_with() で目的の文字列で始まる全ての変数を選びましょう。
Gather には、集めない変数(つまりID変数)を特定する、- シンボルを使う
別の書き方もあります。
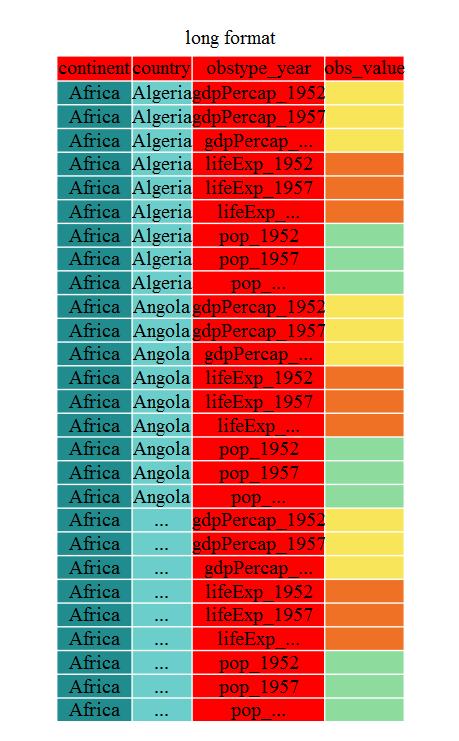
gap_long <- gap_wide %>% gather(obstype_year,obs_values,-continent,-country)
str(gap_long)
'data.frame':\t5112 obs. of 4 variables:
$ continent : chr "Africa" "Africa" "Africa" "Africa" ...
$ country : chr "Algeria" "Angola" "Benin" "Botswana" ...
$ obstype_year: chr "gdpPercap_1952" "gdpPercap_1952" "gdpPercap_1952" "gdpPercap_1952" ...
$ obs_values : num 2449 3521 1063 851 543 ...
これは、このデータフレームでは、取るに足らないことかもしれませんが、 1つの ID 変数と40の変則的な変数名を持つ観測変数がある場合も時にはあります。 柔軟性があることで、かなり時間が節約できるのです!
ここで obstype_year には、実は2種類の情報が含まれています。
観測値の形(pop、lifeExp、又はgdpPercap)及び year です。
文字列を複数の変数に分割するには、 separate() 関数が使えます。
gap_long <- gap_long %>% separate(obstype_year,into=c('obs_type','year'),sep="_")
gap_long$year <- as.integer(gap_long$year)
チャレンジ2
gap_longを使って、各大陸の平均余命、人口及びgdpPercapを計算しましょう。 ヒント:dplyrで習ったgroup_by()とsummarize()関数を使いましょう。チャレンジ2の解答
gap_long %>% group_by(continent,obs_type) %>% summarize(means=mean(obs_values))# A tibble: 15 x 3 # Groups: continent [?] continent obs_type means <chr> <chr> <dbl> 1 Africa gdpPercap 2194. 2 Africa lifeExp 48.9 3 Africa pop 9916003. 4 Americas gdpPercap 7136. 5 Americas lifeExp 64.7 6 Americas pop 24504795. 7 Asia gdpPercap 7902. 8 Asia lifeExp 60.1 9 Asia pop 77038722. 10 Europe gdpPercap 14469. 11 Europe lifeExp 71.9 12 Europe pop 17169765. 13 Oceania gdpPercap 18622. 14 Oceania lifeExp 74.3 15 Oceania pop 8874672.
spread() で縦長から中間形式へ
仕事を確認することは、とても良いことです。 gather() の反対の名は体を表す spread() を使って、
観測変数を元通りに広げてみましょう。そこから gap_long() を、元々の中間形式、又は、
一番横長な形式に広げることもできます。まずは、中間形式から始めましょう。
gap_normal <- gap_long %>% spread(obs_type,obs_values)
dim(gap_normal)
[1] 1704 6
dim(gapminder)
[1] 1704 6
names(gap_normal)
[1] "continent" "country" "year" "gdpPercap" "lifeExp" "pop"
names(gapminder)
[1] "country" "year" "pop" "continent" "lifeExp" "gdpPercap"
元々の gapminder と同じ次元を持つ、中間形式のデータフレーム gap_normal ができましたが、
変数の順番が違います。 このふたつが、 all.equal() かを調べる前に、これを直しましょう。
gap_normal <- gap_normal[,names(gapminder)]
all.equal(gap_normal,gapminder)
[1] "Component \"country\": 1704 string mismatches"
[2] "Component \"pop\": Mean relative difference: 1.634504"
[3] "Component \"continent\": 1212 string mismatches"
[4] "Component \"lifeExp\": Mean relative difference: 0.203822"
[5] "Component \"gdpPercap\": Mean relative difference: 1.162302"
head(gap_normal)
country year pop continent lifeExp gdpPercap
1 Algeria 1952 9279525 Africa 43.077 2449.008
2 Algeria 1957 10270856 Africa 45.685 3013.976
3 Algeria 1962 11000948 Africa 48.303 2550.817
4 Algeria 1967 12760499 Africa 51.407 3246.992
5 Algeria 1972 14760787 Africa 54.518 4182.664
6 Algeria 1977 17152804 Africa 58.014 4910.417
head(gapminder)
country year pop continent lifeExp gdpPercap
1 Afghanistan 1952 8425333 Asia 28.801 779.4453
2 Afghanistan 1957 9240934 Asia 30.332 820.8530
3 Afghanistan 1962 10267083 Asia 31.997 853.1007
4 Afghanistan 1967 11537966 Asia 34.020 836.1971
5 Afghanistan 1972 13079460 Asia 36.088 739.9811
6 Afghanistan 1977 14880372 Asia 38.438 786.1134
もうすぐです。元々のは、 country 、 continent 、そして year でソートされていました。
gap_normal <- gap_normal %>% arrange(country,continent,year)
all.equal(gap_normal,gapminder)
[1] TRUE
すばらしい!一番縦に長い形式から、中間形式に戻し、コードにエラーが でることもありませんでした。
さぁ、縦長のものを、全て横長に戻しましょう。横長の形式で、
国と大陸を、ID変数として置いておいて、3行列(pop、lifeExp、gdpPercap)
及び時間(year)に観測値を分けていきましょう。まず、全ての変数(time*metric の組み合わせ)
に適当なラベルを付ける必要があります。また、gap_wide を定義する処理を簡単にするために、
ID変数たちを統合する必要もあります。
gap_temp <- gap_long %>% unite(var_ID,continent,country,sep="_")
str(gap_temp)
'data.frame':\t5112 obs. of 4 variables:
$ var_ID : chr "Africa_Algeria" "Africa_Angola" "Africa_Benin" "Africa_Botswana" ...
$ obs_type : chr "gdpPercap" "gdpPercap" "gdpPercap" "gdpPercap" ...
$ year : int 1952 1952 1952 1952 1952 1952 1952 1952 1952 1952 ...
$ obs_values: num 2449 3521 1063 851 543 ...
gap_temp <- gap_long %>%
unite(ID_var,continent,country,sep="_") %>%
unite(var_names,obs_type,year,sep="_")
str(gap_temp)
'data.frame':\t5112 obs. of 3 variables:
$ ID_var : chr "Africa_Algeria" "Africa_Angola" "Africa_Benin" "Africa_Botswana" ...
$ var_names : chr "gdpPercap_1952" "gdpPercap_1952" "gdpPercap_1952" "gdpPercap_1952" ...
$ obs_values: num 2449 3521 1063 851 543 ...
unite() を使い、continentとcountryを組み合わせ、ID 変数をひとつ作り、
変数名を定義しました。 spread() でパイプを使う準備が整いました。
gap_wide_new <- gap_long %>%
unite(ID_var,continent,country,sep="_") %>%
unite(var_names,obs_type,year,sep="_") %>%
spread(var_names,obs_values)
str(gap_wide_new)
'data.frame':\t142 obs. of 37 variables:
$ ID_var : chr "Africa_Algeria" "Africa_Angola" "Africa_Benin" "Africa_Botswana" ...
$ gdpPercap_1952: num 2449 3521 1063 851 543 ...
$ gdpPercap_1957: num 3014 3828 960 918 617 ...
$ gdpPercap_1962: num 2551 4269 949 984 723 ...
$ gdpPercap_1967: num 3247 5523 1036 1215 795 ...
$ gdpPercap_1972: num 4183 5473 1086 2264 855 ...
$ gdpPercap_1977: num 4910 3009 1029 3215 743 ...
$ gdpPercap_1982: num 5745 2757 1278 4551 807 ...
$ gdpPercap_1987: num 5681 2430 1226 6206 912 ...
$ gdpPercap_1992: num 5023 2628 1191 7954 932 ...
$ gdpPercap_1997: num 4797 2277 1233 8647 946 ...
$ gdpPercap_2002: num 5288 2773 1373 11004 1038 ...
$ gdpPercap_2007: num 6223 4797 1441 12570 1217 ...
$ lifeExp_1952 : num 43.1 30 38.2 47.6 32 ...
$ lifeExp_1957 : num 45.7 32 40.4 49.6 34.9 ...
$ lifeExp_1962 : num 48.3 34 42.6 51.5 37.8 ...
$ lifeExp_1967 : num 51.4 36 44.9 53.3 40.7 ...
$ lifeExp_1972 : num 54.5 37.9 47 56 43.6 ...
$ lifeExp_1977 : num 58 39.5 49.2 59.3 46.1 ...
$ lifeExp_1982 : num 61.4 39.9 50.9 61.5 48.1 ...
$ lifeExp_1987 : num 65.8 39.9 52.3 63.6 49.6 ...
$ lifeExp_1992 : num 67.7 40.6 53.9 62.7 50.3 ...
$ lifeExp_1997 : num 69.2 41 54.8 52.6 50.3 ...
$ lifeExp_2002 : num 71 41 54.4 46.6 50.6 ...
$ lifeExp_2007 : num 72.3 42.7 56.7 50.7 52.3 ...
$ pop_1952 : num 9279525 4232095 1738315 442308 4469979 ...
$ pop_1957 : num 10270856 4561361 1925173 474639 4713416 ...
$ pop_1962 : num 11000948 4826015 2151895 512764 4919632 ...
$ pop_1967 : num 12760499 5247469 2427334 553541 5127935 ...
$ pop_1972 : num 14760787 5894858 2761407 619351 5433886 ...
$ pop_1977 : num 17152804 6162675 3168267 781472 5889574 ...
$ pop_1982 : num 20033753 7016384 3641603 970347 6634596 ...
$ pop_1987 : num 23254956 7874230 4243788 1151184 7586551 ...
$ pop_1992 : num 26298373 8735988 4981671 1342614 8878303 ...
$ pop_1997 : num 29072015 9875024 6066080 1536536 10352843 ...
$ pop_2002 : num 31287142 10866106 7026113 1630347 12251209 ...
$ pop_2007 : num 33333216 12420476 8078314 1639131 14326203 ...
チャレンジ3
この一つ先に進み、
gap_ludicrously_wideを作り、国、年及び3つの行列に展開したデータを作りましょう。 ヒント この新しいデータフレームには、5行しかありません。チャレンジ3の解答
gap_ludicrously_wide <- gap_long %>% unite(var_names,obs_type,year,country,sep="_") %>% spread(var_names,obs_values)
今、とても ‘横長な’ 形式のデータフレームがありますが、 ID_var は、より使えるようにできるはずです。
separate() を使って、2変数に分けてみましょう。
gap_wide_betterID <- separate(gap_wide_new,ID_var,c("continent","country"),sep="_")
gap_wide_betterID <- gap_long %>%
unite(ID_var, continent,country,sep="_") %>%
unite(var_names, obs_type,year,sep="_") %>%
spread(var_names, obs_values) %>%
separate(ID_var, c("continent","country"),sep="_")
str(gap_wide_betterID)
'data.frame':\t142 obs. of 38 variables:
$ continent : chr "Africa" "Africa" "Africa" "Africa" ...
$ country : chr "Algeria" "Angola" "Benin" "Botswana" ...
$ gdpPercap_1952: num 2449 3521 1063 851 543 ...
$ gdpPercap_1957: num 3014 3828 960 918 617 ...
$ gdpPercap_1962: num 2551 4269 949 984 723 ...
$ gdpPercap_1967: num 3247 5523 1036 1215 795 ...
$ gdpPercap_1972: num 4183 5473 1086 2264 855 ...
$ gdpPercap_1977: num 4910 3009 1029 3215 743 ...
$ gdpPercap_1982: num 5745 2757 1278 4551 807 ...
$ gdpPercap_1987: num 5681 2430 1226 6206 912 ...
$ gdpPercap_1992: num 5023 2628 1191 7954 932 ...
$ gdpPercap_1997: num 4797 2277 1233 8647 946 ...
$ gdpPercap_2002: num 5288 2773 1373 11004 1038 ...
$ gdpPercap_2007: num 6223 4797 1441 12570 1217 ...
$ lifeExp_1952 : num 43.1 30 38.2 47.6 32 ...
$ lifeExp_1957 : num 45.7 32 40.4 49.6 34.9 ...
$ lifeExp_1962 : num 48.3 34 42.6 51.5 37.8 ...
$ lifeExp_1967 : num 51.4 36 44.9 53.3 40.7 ...
$ lifeExp_1972 : num 54.5 37.9 47 56 43.6 ...
$ lifeExp_1977 : num 58 39.5 49.2 59.3 46.1 ...
$ lifeExp_1982 : num 61.4 39.9 50.9 61.5 48.1 ...
$ lifeExp_1987 : num 65.8 39.9 52.3 63.6 49.6 ...
$ lifeExp_1992 : num 67.7 40.6 53.9 62.7 50.3 ...
$ lifeExp_1997 : num 69.2 41 54.8 52.6 50.3 ...
$ lifeExp_2002 : num 71 41 54.4 46.6 50.6 ...
$ lifeExp_2007 : num 72.3 42.7 56.7 50.7 52.3 ...
$ pop_1952 : num 9279525 4232095 1738315 442308 4469979 ...
$ pop_1957 : num 10270856 4561361 1925173 474639 4713416 ...
$ pop_1962 : num 11000948 4826015 2151895 512764 4919632 ...
$ pop_1967 : num 12760499 5247469 2427334 553541 5127935 ...
$ pop_1972 : num 14760787 5894858 2761407 619351 5433886 ...
$ pop_1977 : num 17152804 6162675 3168267 781472 5889574 ...
$ pop_1982 : num 20033753 7016384 3641603 970347 6634596 ...
$ pop_1987 : num 23254956 7874230 4243788 1151184 7586551 ...
$ pop_1992 : num 26298373 8735988 4981671 1342614 8878303 ...
$ pop_1997 : num 29072015 9875024 6066080 1536536 10352843 ...
$ pop_2002 : num 31287142 10866106 7026113 1630347 12251209 ...
$ pop_2007 : num 33333216 12420476 8078314 1639131 14326203 ...
all.equal(gap_wide, gap_wide_betterID)
[1] TRUE
そこにまた戻りました!
その他役に立つ資料
- R for Data Science
- Data Wrangling Cheat sheet
- Introduction to tidyr
- Data wrangling with R and RStudio
まとめ
データフレームの形式を変更するには
tidyrを使用する。「横長」から「縦長」に変換するには
gather()を使用する。「縦長」から「横長」に変換するには
spread()を使用する。