dplyrによるデータフレームの操作
概要
講義: 40 分
演習: 15 分質問
同じ作業を繰り返すことなく、データフレームを操作するにはどうすればよいです?
目標
dplyrにある6つの操作をパイプを使用して出来るようになりましょう。データセットを要約するために
group_by()とsummarize()併用出来ることを理解しましょう。論理フィルターを使用してデータのサブセットを分析出来るようになりましょう。
多くの研究者にとって、データフレームの操作は、多くのことを意味します。 よくあるのは、特定の観測値(行)もしくは変数(列)の選択、 特定の変数でのデータのグループ化、 更には要約する統計値の計算です。 これらは、普通のRの基本操作で実行できます:
mean(gapminder[gapminder$continent == "Africa", "gdpPercap"])
[1] 2193.755
mean(gapminder[gapminder$continent == "Americas", "gdpPercap"])
[1] 7136.11
mean(gapminder[gapminder$continent == "Asia", "gdpPercap"])
[1] 7902.15
でも、これはあまりおススメではありません。繰り返しがかなりあるからです。 繰り返し作業は、時間を食います。そして、嫌なバグを起こる原因にもなりえます。
dplyr パッケージ
嬉しいことに、dplyr
パッケージには、データフレーム操作に非常に役立つ関数がいくつもあります。
それを使うと、先ほどみたような繰り返しを減らし、エラーを起こす確率を減らし、
タイピングする必要性さえも恐らく減らせます。
更には、dplyr の書き方は、とても分かりやすいかもしれません。
ここでは、特によく使われる6つの関数と、
それらを組み合わせるためのパイプ(%>%)を紹介します。
.
select()filter()group_by()summarize()mutate()
もし、このパッケージをまだインストールしていないようでしたら、ここでしておきましょう:
install.packages('dplyr')
パッケージをロードしましょう:
library("dplyr")
select() の使用
例えば、 データフレームにある、いくつかの変数だけを使って進めたい場合、
使えるかもしれないのは、select() 関数です。
これを使えば、選択した変数だけをキープすることができます。
year_country_gdp <- select(gapminder,year,country,gdpPercap)
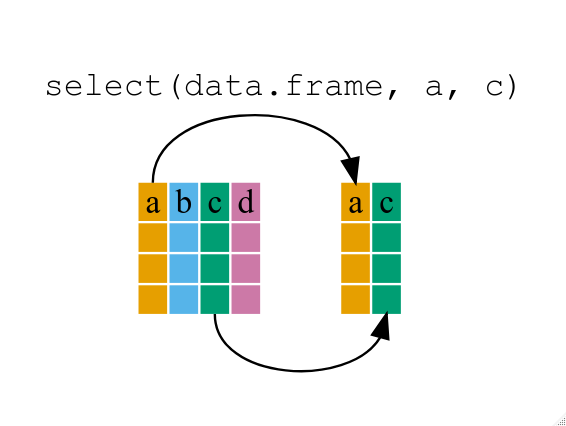
もし year_country_gdp を開いたら、year、country 及び gdpPercap しかないでしょう。
これまでは、 ‘普通の’ 書き方を使いましたが、dplyr の強みは、複数の関数を
パイプを使って、組み合わせられることです。
パイプの書き方は、これまでRで見てきたものとは、
全く違いますので、上記でしたことをパイプを使って、やってみましょう。
year_country_gdp <- gapminder %>% select(year,country,gdpPercap)
こう書いた理由を理解しやすくするために、ひとつずつ見ていきましょう。
始めに、gapminder データフレームを呼び出し、パイプの記号%>% を使って、
次の select() 関数を使うステップに引き渡します。どのデータオブジェクトを
select() 関数で使うかについては、前のパイプから分かるため、ここでは指定しません。
面白い事実:シェルで、パイプに既に出会っている可能性が高いはずです。
Rでは、パイプの記号は %>% で、シェルでは、 | ですが、コンセプトは同じです。
filter() の使用
欧州のみで、上記を進めたいとしたら、 select と filter を組み合わせましょう。
year_country_gdp_euro <- gapminder %>%
filter(continent=="Europe") %>%
select(year,country,gdpPercap)
チャレンジ1
アフリカの
lifeExp、country及びyearを持ち、他の大陸を含まないデータフレームを 作るコマンドをひとつ書いてみましょう(複数の行になっても、パイプを使っても大丈夫です) データフレームには、何行ありますか。なぜそうなるのでしょうか。チャレンジ1の解答
year_country_lifeExp_Africa <- gapminder %>% filter(continent=="Africa") %>% select(year,country,lifeExp)
以前行ったように、gapminder データフレームを filter() 関数に引き渡し、
フィルターされた バージョンのgapminder データフレームを、 select() 関数に引き渡します。
注意: ここでは、操作手順がとても重要です。
まず ‘select’ を使うと、その前のステップで、大陸の変数が削除されているため、
filter で大陸の変数を見つけることができないことでしょう。
group_by() と summarize() の使用
ここでは、Rの基本的な機能を用いたエラーが起こりやすい繰り返し作業を減らすはずでした。
でも、まだそれが達成できていません。上記では、それぞれの大陸ごとに同じことを繰り返さなければならないからです。
繰り返しを無くすために、(上記の continent=="Europe" のように)条件にあったデータのみを引き渡す filter() の代わりに、
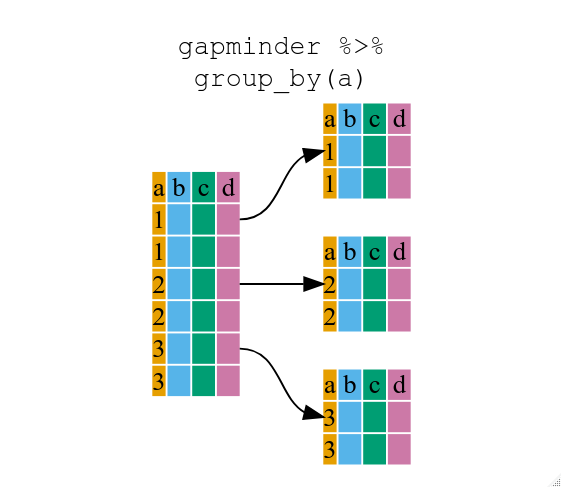
filterでも使える、それぞれの一意の条件を元に一気にデータを分ける group_by() を使うこともできます。
str(gapminder)
'data.frame':\t1704 obs. of 6 variables:
$ country : Factor w/ 142 levels "Afghanistan",..: 1 1 1 1 1 1 1 1 1 1 ...
$ year : int 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 ...
$ pop : num 8425333 9240934 10267083 11537966 13079460 ...
$ continent: Factor w/ 5 levels "Africa","Americas",..: 3 3 3 3 3 3 3 3 3 3 ...
$ lifeExp : num 28.8 30.3 32 34 36.1 ...
$ gdpPercap: num 779 821 853 836 740 ...
str(gapminder %>% group_by(continent))
Classes 'grouped_df', 'tbl_df', 'tbl' and 'data.frame':\t1704 obs. of 6 variables:
$ country : Factor w/ 142 levels "Afghanistan",..: 1 1 1 1 1 1 1 1 1 1 ...
$ year : int 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 ...
$ pop : num 8425333 9240934 10267083 11537966 13079460 ...
$ continent: Factor w/ 5 levels "Africa","Americas",..: 3 3 3 3 3 3 3 3 3 3 ...
$ lifeExp : num 28.8 30.3 32 34 36.1 ...
$ gdpPercap: num 779 821 853 836 740 ...
- attr(*, "vars")= chr "continent"
- attr(*, "drop")= logi TRUE
- attr(*, "indices")=List of 5
..$ : int 24 25 26 27 28 29 30 31 32 33 ...
..$ : int 48 49 50 51 52 53 54 55 56 57 ...
..$ : int 0 1 2 3 4 5 6 7 8 9 ...
..$ : int 12 13 14 15 16 17 18 19 20 21 ...
..$ : int 60 61 62 63 64 65 66 67 68 69 ...
- attr(*, "group_sizes")= int 624 300 396 360 24
- attr(*, "biggest_group_size")= int 624
- attr(*, "labels")='data.frame':\t5 obs. of 1 variable:
..$ continent: Factor w/ 5 levels "Africa","Americas",..: 1 2 3 4 5
..- attr(*, "vars")= chr "continent"
..- attr(*, "drop")= logi TRUE
group_by() (grouped_df)で用いたデータフレームのデータ構造は、もともとの gapminder (data.frame)とは異なることに気づいたことでしょう。
grouped_df は、 list のようなものです。その list にある各項目は、
(少なくとも上記の例では)特定の continent の値が対応する列のみを含む data.frame
になります。
summarize() の使用
上記は、少し物足りないかもしれませんが、group_by() は、summarize() と共に使えば
本当にすばらしいのです。それぞれの大陸のデータフレームごとに繰り返す関数を使って、
新たな変数を作ることができます。
つまり、 group_by() 関数を使って、もともとのデータフレームを、いくつかのデータに分け、
summarize() の中で、関数(たとえば mean() や sd())を実行することができるのです。
gdp_bycontinents <- gapminder %>%
group_by(continent) %>%
summarize(mean_gdpPercap=mean(gdpPercap))
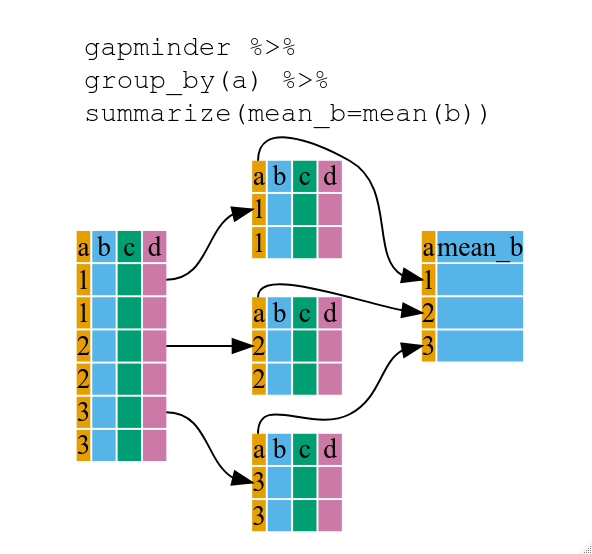
continent mean_gdpPercap
<fctr> <dbl>
1 Africa 2193.755
2 Americas 7136.110
3 Asia 7902.150
4 Europe 14469.476
5 Oceania 18621.609
これにより、それぞれの大陸の平均gdpPercapを計算することができますが、 更に、すばらしいことがあるのです。
チャレンジ2
国別平均余命を計算しましょう。平均余命が、一番長い国と一番短い国は、 それぞれどこでしょうか。
チャレンジ2の解答
lifeExp_bycountry <- gapminder %>% group_by(country) %>% summarize(mean_lifeExp=mean(lifeExp)) lifeExp_bycountry %>% filter(mean_lifeExp == min(mean_lifeExp) | mean_lifeExp == max(mean_lifeExp))# A tibble: 2 x 2 country mean_lifeExp <fct> <dbl> 1 Iceland 76.5 2 Sierra Leone 36.8もうひとつの方法は、
dplyrの関数arrange()を使うことです。 これは、データフレームのひとつ又は複数の変数の順序に従って、 データフレームの列を配置するものです。 書き方は、dplyrパッケージの 他の関数と似ています。降順で並べたいときは、arrange()の中に、desc()を使えばよいのです。lifeExp_bycountry %>% arrange(mean_lifeExp) %>% head(1)# A tibble: 1 x 2 country mean_lifeExp <fct> <dbl> 1 Sierra Leone 36.8lifeExp_bycountry %>% arrange(desc(mean_lifeExp)) %>% head(1)# A tibble: 1 x 2 country mean_lifeExp <fct> <dbl> 1 Iceland 76.5
group_by() の関数では、複数の変数でグループ化するこもできます。
year と continent でグループ分けしてみましょう。
gdp_bycontinents_byyear <- gapminder %>%
group_by(continent,year) %>%
summarize(mean_gdpPercap=mean(gdpPercap))
これでも、かなり役に立ちますが、更にすごいことに、summarize() の中で新しく定義できる変数は、1つに限らないのです。
gdp_pop_bycontinents_byyear <- gapminder %>%
group_by(continent,year) %>%
summarize(mean_gdpPercap=mean(gdpPercap),
sd_gdpPercap=sd(gdpPercap),
mean_pop=mean(pop),
sd_pop=sd(pop))
count() 及び n()
よくありがちな操作は、各グループの観測値の数を数えることですが、 ‘dplyr’ パッケージには、これに役立つ関数が2つあります。
例えば、2002年のデータセットにある国の数を確認したい場合、 count() 関数が使えます。
興味のあるグループのひとつかいくつかの行の名前を取り、
sort=TRUE を加えることで、結果を降順に並べることもできます:
gapminder %>%
filter(year == 2002) %>%
count(continent, sort = TRUE)
# A tibble: 5 x 2
continent n
<fct> <int>
1 Africa 52
2 Asia 33
3 Europe 30
4 Americas 25
5 Oceania 2
演算の際の観測値の数が必要な場合 n() 関数が使えます。
例えば、大陸別平均余命の標準誤差を得たいとします:
gapminder %>%
group_by(continent) %>%
summarize(se_le = sd(lifeExp)/sqrt(n()))
# A tibble: 5 x 2
continent se_le
<fct> <dbl>
1 Africa 0.366
2 Americas 0.540
3 Asia 0.596
4 Europe 0.286
5 Oceania 0.775
いくつかの要約計算を、つなぎ合わせることもできます。つまり、ここでは各大陸の国別平均余命の minimum 、 maximum 、 mean 及び se となります:
gapminder %>%
group_by(continent) %>%
summarize(
mean_le = mean(lifeExp),
min_le = min(lifeExp),
max_le = max(lifeExp),
se_le = sd(lifeExp)/sqrt(n()))
# A tibble: 5 x 5
continent mean_le min_le max_le se_le
<fct> <dbl> <dbl> <dbl> <dbl>
1 Africa 48.9 23.6 76.4 0.366
2 Americas 64.7 37.6 80.7 0.540
3 Asia 60.1 28.8 82.6 0.596
4 Europe 71.9 43.6 81.8 0.286
5 Oceania 74.3 69.1 81.2 0.775
mutate() の使用
情報を要約する前に(もしくは後にでも)、 mutate() を使えば、新しい変数を作ることができます。
gdp_pop_bycontinents_byyear <- gapminder %>%
mutate(gdp_billion=gdpPercap*pop/10^9) %>%
group_by(continent,year) %>%
summarize(mean_gdpPercap=mean(gdpPercap),
sd_gdpPercap=sd(gdpPercap),
mean_pop=mean(pop),
sd_pop=sd(pop),
mean_gdp_billion=mean(gdp_billion),
sd_gdp_billion=sd(gdp_billion))
論理フィルター ifelse とmutate の併用
新しい変数を作る時、論理条件を付けることができます。
似たような組み合わせの mutate() と ifelse() は、まさに必要な場面、つまり
新しいものを作る時に、フィルターすることができます。
この簡単に読めるコードが、(データフレーム全体の次元を変えずに)あるデータを
排除するための早くて役に立つ方法であり、
与えられた条件によって値を更新する方法なのです。
## keeping all data but "filtering" after a certain condition
# calculate GDP only for people with a life expectation above 25
gdp_pop_bycontinents_byyear_above25 <- gapminder %>%
mutate(gdp_billion = ifelse(lifeExp > 25, gdpPercap * pop / 10^9, NA)) %>%
group_by(continent, year) %>%
summarize(mean_gdpPercap = mean(gdpPercap),
sd_gdpPercap = sd(gdpPercap),
mean_pop = mean(pop),
sd_pop = sd(pop),
mean_gdp_billion = mean(gdp_billion),
sd_gdp_billion = sd(gdp_billion))
## updating only if certain condition is fullfilled
# for life expectations above 40 years, the gpd to be expected in the future is scaled
gdp_future_bycontinents_byyear_high_lifeExp <- gapminder %>%
mutate(gdp_futureExpectation = ifelse(lifeExp > 40, gdpPercap * 1.5, gdpPercap)) %>%
group_by(continent, year) %>%
summarize(mean_gdpPercap = mean(gdpPercap),
mean_gdpPercap_expected = mean(gdp_futureExpectation))
dplyr と ggplot2 の併用
プロットのレッスンでは、 ggplot2 を使って、ファセットパネルの層を加えることで、
複数パネルの図を示す方法を見ました。
以下が、(いくつかコメントを足してありますが)使用したコードです:
# Get the start letter of each country
starts.with <- substr(gapminder$country, start = 1, stop = 1)
# Filter countries that start with "A" or "Z"
az.countries <- gapminder[starts.with %in% c("A", "Z"), ]
# Make the plot
ggplot(data = az.countries, aes(x = year, y = lifeExp, color = continent)) +
geom_line() + facet_wrap( ~ country)

このコードは、正しいプロットを作りますが、他に使い道のない、変数(starts.with
及び az.countries)も作ります。 dplyr 関数のチェーンで、 %>% を使って、
データをパイプしたように、 ggplot() へデータを引き渡すこともできます。
なぜならば %>% は、関数の最初の引数を置き換えるため、
ggplot() 関数の中の、 data = 因数を指定する必要がありません。
dplyr と ggplot2 関数を組み合わせることで、同じ図を、新しい変数を作ったり、
データを修正することなく作成できます。
gapminder %>%
# Get the start letter of each country
mutate(startsWith = substr(country, start = 1, stop = 1)) %>%
# Filter countries that start with "A" or "Z"
filter(startsWith %in% c("A", "Z")) %>%
# Make the plot
ggplot(aes(x = year, y = lifeExp, color = continent)) +
geom_line() +
facet_wrap( ~ country)

dplyr 関数を使うことで、物事が簡単になります。例えば、
最初の2つの段階を組み合わせることができます:
gapminder %>%
# Filter countries that start with "A" or "Z"
\tfilter(substr(country, start = 1, stop = 1) %in% c("A", "Z")) %>%
\t# Make the plot
\tggplot(aes(x = year, y = lifeExp, color = continent)) +
\tgeom_line() +
\tfacet_wrap( ~ country)

上級チャレンジ
各大陸から無作為に選ばれた2つの国の2002年の平均余命を計算し、 大陸名を、逆の順番に並べましょう。 ヒント:
dplyr関数arrange()及びsample_n()を使いましょう。 書き方は、他の dplyr 関数と同じです。上級チャレンジの解答
lifeExp_2countries_bycontinents <- gapminder %>% filter(year==2002) %>% group_by(continent) %>% sample_n(2) %>% summarize(mean_lifeExp=mean(lifeExp)) %>% arrange(desc(mean_lifeExp))
その他役に立つ資料
- R for Data Science
- Data Wrangling Cheat sheet
- Introduction to dplyr
- Data wrangling with R and RStudio
まとめ
dplyrパッケージを使用してデータフレームの操作を行う。データフレームから変数を選択する際は
select()を使用する。値を基にデータを選択する際は
filter()を使用する。部分化されたデータを操作する際は
group_by()やsummarize()を使用する。新しい変数を作成する際は
mutate()を使用する。