plyr によるデータフレームの分離と併合
概要
講義: 30 分
演習: 30 分質問
異なるデータセットに異なる計算を施すにはどうすればよいですか?
目標
split-apply-combine (分離-施工-併合)をデータ分析に使えるようになりましょう。
ここまでに、関数がコードをシンプルにするために使えるということをお伝えしました。
gapminder データセットを使って、人口の列と1人当たりのGDP(国内総生産)の列を掛ける
関数 calcGDP を定義し、更に、
year と country でフィルターできる引数を追加で、定義しましたよね。
# データセットを受け取り、人口の列と一人あたりのGDPの列をかけます。
calcGDP <- function(dat, year=NULL, country=NULL) {
if(!is.null(year)) {
dat <- dat[dat$year %in% year, ]
}
if (!is.null(country)) {
dat <- dat[dat$country %in% country,]
}
gdp <- dat$pop * dat$gdpPercap
new <- cbind(dat, gdp=gdp)
return(new)
}
データを使うときに、データにあるグループごとに計算を実行してみたいと思うことが、よくあります。 先ほどの例では、単純に二つの列を掛け合わせることでGDPを計算しました。 では、大陸ごとに平均GDPを計算したいときは、どうすればよいでしょうか。
calcGDP を実行してから、それぞれの大陸の平均をとることもできます:
withGDP <- calcGDP(gapminder)
mean(withGDP[withGDP$continent == "Africa", "gdp"])
[1] 20904782844
mean(withGDP[withGDP$continent == "Americas", "gdp"])
[1] 379262350210
mean(withGDP[withGDP$continent == "Asia", "gdp"])
[1] 227233738153
でも、これはあまりおススメではありません。そうです。ある関数を使えば、 いくつもの繰り返し作業を減らすことができます。それ は、おススメです。 それでも、繰り返し作業はあります。繰り返し作業は、その時点だけでなく その後も、時間を食います。そして、嫌なバグが起こる原因にもなりえます。
calcGDP のような、新しい関数を書くこともできます。
でも、ちゃんとしたものを作るには、かなりの労力と確認が必要になるでしょう。
ここで直面している抽象的な問題は、 「split-apply-combine(分けてー適用してーまとめる)」ものとしてよく知られています:
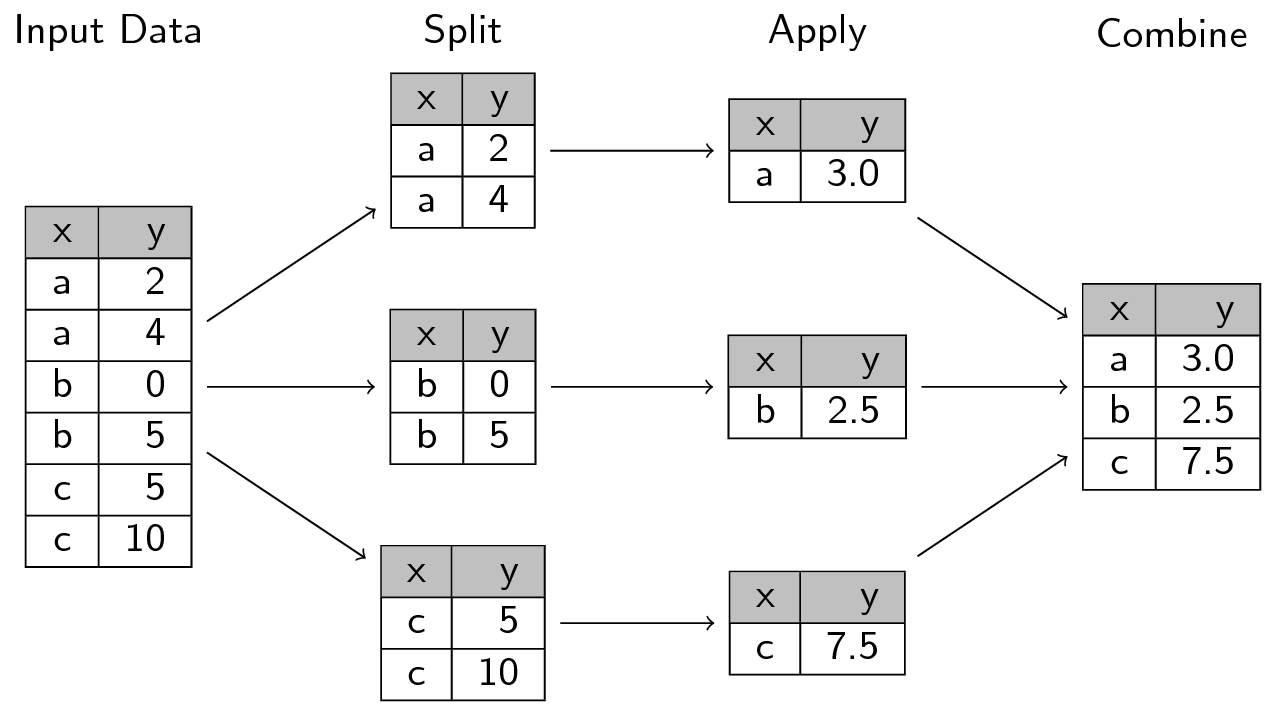
データを(この例では大陸別に)グループ 分け し、そのグループへある計算を 適用し、できればその後に、結果を まとめ たいのです。
plyr パッケージ
Rを使ったことがある人なら、apply系の関数は、既にご存知かもしれません。
Rに元々ある関数でもよいのですが、この「split-apply-combine」問題を解決する
他の方法を紹介しましょう。
plyr パッケージには、よりお手軽に、
この問題を解決できる関数たちがあります。
このパッケージを、以前のチャレンジで、インストールしましたので、ここでロードしてみましょう:
library("plyr")
Plyrには、lists(リスト)、data.frames(データフレーム) 及び arrays(列)(行列またはn-次元のベクトル)
に実行できる関数があります。それぞれの関数は以下を実行します:
- 分ける 作業
- 分割したそれぞれへの関数の 適用
- 出力データを再度ひとつのデータオブジェクトとしてまとめる
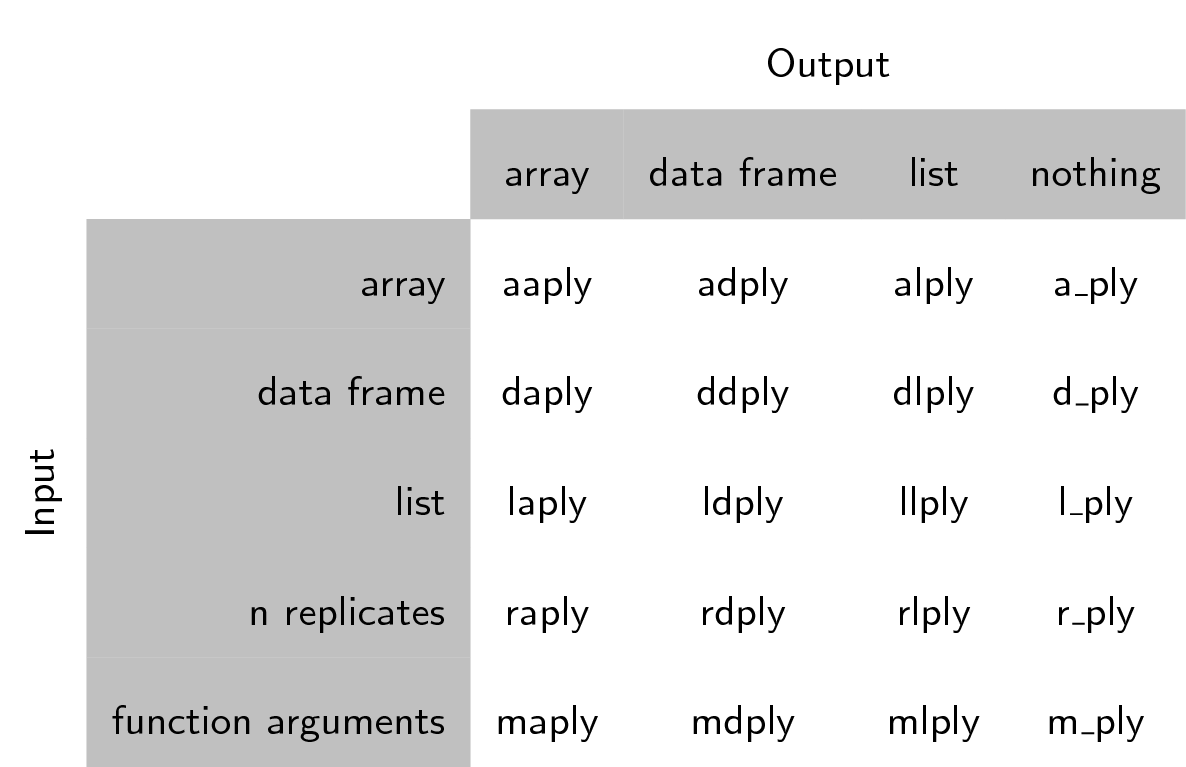
関数は、入力されるだろうデータ構造と出力予定のデータ構造に基づき名付けられています。 つまり、[a]rray、[l]ist、または[d]ata.frameのことです。最初の文字が、入力データ構造、 次の文字が出力データ構造、そして、残りが「ply」と名付けられた関数です。
これが **plyの9つの中心的な関数です。加えて、分けて適用することだけで、まとめを実行しない
関数が3つあります。それらは、入力データ型と出力データがないことを示す
_ から名付けられています(表参照)。
ここで、plyrの「array」の使用法は、Rの使用法と違うことに気をつけましょう。 plyのarrayは、ベクトルや行列も含めます。
xxply関数(daply 、 ddply 、 llply 、 laply、などなど)は、
同じ構造で、4つの重要な特徴と構造を持っています:
xxply(.data, .variables, .fun)
- 関数名の最初の文字が、入力型、次の文字が出力型を示します。
- .data -処理されるデータオブジェクトを示します。
- .variables-分割する変数を指定します。
- .fun-それぞれに適用する関数を示します。
それでは、大陸別の平均GDPを計算してみましょう:
ddply(
.data = calcGDP(gapminder),
.variables = "continent",
.fun = function(x) mean(x$gdp)
)
continent V1
1 Africa 20904782844
2 Americas 379262350210
3 Asia 227233738153
4 Europe 269442085301
5 Oceania 188187105354
このコードを、ひとつずつ見てみましょう:
ddply関数は、data.frameを使い(関数は、dから始まりますね)、 もうひとつのdata.frameを出力します(2番目の文字は、dですね)- 最初の引数は、使いたいdata.frameでしたね。つまり、ここでは、
gapminderデータです。そこに、
gdp(国内総生産) の列を加えるために、まずcalcGDPを使いましょう。 - 次の引数は、分割基準を、つまり、ここでは「continent」(大陸)列です。 以前、分部集合に分けるときに使った値の名前ではなく、ここでは列の名前を使うことに気を付けましょう。Plyrが細かい実行上の詳細を、代わりに処理してくれますので。
- 3番目の引数は、データのそれぞれのグループに当てはめる関数です。
ここで、自分で短い関数を定義しておかなければなりません。
データのそれぞれの部分集合が、その関数の最初の引数の
xに保存されます。 これは、名前のない関数です。つまり、他のところで定義していないもので、名前がないものです。それは、ddplyが呼び出されている間だけ、存在します。
チャレンジ1
大陸別の平均余命を計算してみましょう。一番長いのはどこでしょうか。 一番短いのはどこでしょうか。
他のデータ構造型での出力が良い場合は、どうすればよいでしょうか。
dlply(
.data = calcGDP(gapminder),
.variables = "continent",
.fun = function(x) mean(x$gdp)
)
$Africa
[1] 20904782844
$Americas
[1] 379262350210
$Asia
[1] 227233738153
$Europe
[1] 269442085301
$Oceania
[1] 188187105354
attr(,"split_type")
[1] "data.frame"
attr(,"split_labels")
continent
1 Africa
2 Americas
3 Asia
4 Europe
5 Oceania
また同じ関数を呼び出しましたが、2番目の文字を l に変えたので、
出力されたのは、リストでした。
以下で、グループにまとめる列を指定します:
ddply(
.data = calcGDP(gapminder),
.variables = c("continent", "year"),
.fun = function(x) mean(x$gdp)
)
continent year V1
1 Africa 1952 5992294608
2 Africa 1957 7359188796
3 Africa 1962 8784876958
4 Africa 1967 11443994101
5 Africa 1972 15072241974
6 Africa 1977 18694898732
7 Africa 1982 22040401045
8 Africa 1987 24107264108
9 Africa 1992 26256977719
10 Africa 1997 30023173824
11 Africa 2002 35303511424
12 Africa 2007 45778570846
13 Americas 1952 117738997171
14 Americas 1957 140817061264
15 Americas 1962 169153069442
16 Americas 1967 217867530844
17 Americas 1972 268159178814
18 Americas 1977 324085389022
19 Americas 1982 363314008350
20 Americas 1987 439447790357
21 Americas 1992 489899820623
22 Americas 1997 582693307146
23 Americas 2002 661248623419
24 Americas 2007 776723426068
25 Asia 1952 34095762661
26 Asia 1957 47267432088
27 Asia 1962 60136869012
28 Asia 1967 84648519224
29 Asia 1972 124385747313
30 Asia 1977 159802590186
31 Asia 1982 194429049919
32 Asia 1987 241784763369
33 Asia 1992 307100497486
34 Asia 1997 387597655323
35 Asia 2002 458042336179
36 Asia 2007 627513635079
37 Europe 1952 84971341466
38 Europe 1957 109989505140
39 Europe 1962 138984693095
40 Europe 1967 173366641137
41 Europe 1972 218691462733
42 Europe 1977 255367522034
43 Europe 1982 279484077072
44 Europe 1987 316507473546
45 Europe 1992 342703247405
46 Europe 1997 383606933833
47 Europe 2002 436448815097
48 Europe 2007 493183311052
49 Oceania 1952 54157223944
50 Oceania 1957 66826828013
51 Oceania 1962 82336453245
52 Oceania 1967 105958863585
53 Oceania 1972 134112109227
54 Oceania 1977 154707711162
55 Oceania 1982 176177151380
56 Oceania 1987 209451563998
57 Oceania 1992 236319179826
58 Oceania 1997 289304255183
59 Oceania 2002 345236880176
60 Oceania 2007 403657044512
daply(
.data = calcGDP(gapminder),
.variables = c("continent", "year"),
.fun = function(x) mean(x$gdp)
)
year
continent 1952 1957 1962 1967
Africa 5992294608 7359188796 8784876958 11443994101
Americas 117738997171 140817061264 169153069442 217867530844
Asia 34095762661 47267432088 60136869012 84648519224
Europe 84971341466 109989505140 138984693095 173366641137
Oceania 54157223944 66826828013 82336453245 105958863585
year
continent 1972 1977 1982 1987
Africa 15072241974 18694898732 22040401045 24107264108
Americas 268159178814 324085389022 363314008350 439447790357
Asia 124385747313 159802590186 194429049919 241784763369
Europe 218691462733 255367522034 279484077072 316507473546
Oceania 134112109227 154707711162 176177151380 209451563998
year
continent 1992 1997 2002 2007
Africa 26256977719 30023173824 35303511424 45778570846
Americas 489899820623 582693307146 661248623419 776723426068
Asia 307100497486 387597655323 458042336179 627513635079
Europe 342703247405 383606933833 436448815097 493183311052
Oceania 236319179826 289304255183 345236880176 403657044512
これらの関数は for ループの代わりに使えます(その方が、普通は早いです)。
そうするには、for ループの本体の中にあったコードを名無し関数に入れましょう。
d_ply(
.data=gapminder,
.variables = "continent",
.fun = function(x) {
meanGDPperCap <- mean(x$gdpPercap)
print(paste(
"The mean GDP per capita for", unique(x$continent),
"is", format(meanGDPperCap, big.mark=",")
))
}
)
[1] "The mean GDP per capita for Africa is 2,193.755"
[1] "The mean GDP per capita for Americas is 7,136.11"
[1] "The mean GDP per capita for Asia is 7,902.15"
[1] "The mean GDP per capita for Europe is 14,469.48"
[1] "The mean GDP per capita for Oceania is 18,621.61"
ヒント:数を出力する
format関数を使えば、数値をメッセージの中で「いい感じ」に 出力できます。
チャレンジ2
年次の大陸別平均余命を計算しましょう。2007年に 一番長かったのは、短かったのは、どこでしょうか。 1952年から2007にかけて変化が一番大きかったのはどこでしょうか。
上級チャレンジ
plyr関数のひとつを使って、チャレンジ2の出力から、 2007年と1952年の平均余命の差を計算しましょう。
チャレンジの別バージョン(クラスがなくなっていた場合)
実行せずに、以下の中から、大陸別の平均余命を計算するものを選んでみましょう。 :
1.
ddply( .data = gapminder, .variables = gapminder$continent, .fun = function(dataGroup) { mean(dataGroup$lifeExp) } )2.
ddply( .data = gapminder, .variables = "continent", .fun = mean(dataGroup$lifeExp) )3.
ddply( .data = gapminder, .variables = "continent", .fun = function(dataGroup) { mean(dataGroup$lifeExp) } )4.
adply( .data = gapminder, .variables = "continent", .fun = function(dataGroup) { mean(dataGroup$lifeExp) } )
まとめ
plyerパッケージを使用して、データの分離、部分化されたデータに関数の適用、そして結果を併合する。