データの部分集合化
概要
講義: 35 分
演習: 15 分質問
データの部分集合化を R で行うにはどのようにすればいいですか?
目標
ベクター、ファクター、マトリックス、リスト、およびデータフレームの部分化が出来るようになりましょう。
インデックス、名前、および比較演算子を使用してデータ内の個々および複数の要素を取り出せるようになりましょう。
様々なデータ構造の要素のスキップや削除が出来るようになりましょう。
Rには便利な部分集合の演算子が多く含まれています。これらをマスターできれば、 どんなデータセットにも複雑な演算を楽に行えます。
オブジェクトを部分集合する方法は6つあり、データ構造を 部分集合する方法は3つあります。
Rの働き頭、数値ベクトルから始めましょう。
x <- c(5.4, 6.2, 7.1, 4.8, 7.5)
names(x) <- c('a', 'b', 'c', 'd', 'e')
x
a b c d e
5.4 6.2 7.1 4.8 7.5
原子ベクトル
Rでは、文字列、数値、論理値を含む単純なベクトルは、原子(atomic) ベクトルと呼ばれています。その理由は、原子ベクトルはそれ以上単純化できないからです。
練習用のベクトルを作ることができたのですが、どうやってベクトルの中身を使うのでしょう?
要素番号で要素を使う
ベクトルの要素を抽出するためには、対応する1から始まる要素番号を使います:
x[1]
a
5.4
x[4]
d
4.8
違うふうに見えるかもしれませんが、各括弧の演算子は関数です。ベクトル(及び行列)の場合は、 「n番目の要素をちょうだい」ということを意味しています。
複数の要素を一度に頼むこともできます:
x[c(1, 3)]
a c
5.4 7.1
または、ベクトルのスライスを頼むこともできます:
x[1:4]
a b c d
5.4 6.2 7.1 4.8
この : 演算子は、左から右の要素の一連番号を作ります。
1:4
[1] 1 2 3 4
c(1, 2, 3, 4)
[1] 1 2 3 4
同じ要素を何度も頼むこともできます:
x[c(1,1,3)]
a a c
5.4 5.4 7.1
もしベクトルの長さ以上の要素番号を頼んだ場合、Rは欠測値を返します:
x[6]
<NA>
NA
これは、 NA を含む、NA という名前の長さ1のベクトルです。
もし、0番目の要素を頼んだ場合、空ベクトルが返ってきます:
x[0]
named numeric(0)
Rのベクトル番号は、1から始まる
多くのプログラミング言語(例えば、C、Python)では、ベクトルの最初の 要素の要素番号は0です。Rでは、最初の要素番号は1です。
要素を飛ばす、削除する
もし、負の番号をベクトルの要素番号として使った場合、Rは指定された番号 以外の 全ての要素を返します:
x[-2]
a c d e
5.4 7.1 4.8 7.5
複数の要素を飛ばすこともできます:
x[c(-1, -5)] # or x[-c(1,5)]
b c d
6.2 7.1 4.8
ヒント:演算の順番
初心者によく見られるのが、ベクトルのスライスを飛ばそうとする時に起こる間違いです。 数列をベクトルから削除しようとする場合、次のようにして削除しようとします:
x[-1:3]すると、なんだか複雑なエラーが返ってきます:
Error in x[-1:3]: only 0's may be mixed with negative subscripts演算の順番を思い出してみましょう。
:は、実際には関数なのです。 最初の引数を-1、次の引数を3として認識し、次のような数列を生成します。c(-1, 0, 1, 2, 3)正解は、関数を呼ぶ部分を括弧で囲むことです。 そうすると関数の結果全てに
-の演算子が適応されます:x[-(1:3)]d e 4.8 7.5
ベクトルから要素を削除するには、結果を変数に戻してやる必要があります。
x <- x[-4]
x
a b c e
5.4 6.2 7.1 7.5
チャレンジ1
以下のコードがあるとします:
x <- c(5.4, 6.2, 7.1, 4.8, 7.5) names(x) <- c('a', 'b', 'c', 'd', 'e') print(x)a b c d e 5.4 6.2 7.1 4.8 7.5以下の出力を得るために、少なくとも2つの異なるコマンドを考えてください:
b c d 6.2 7.1 4.82つの異なるコマンドを考えた後、隣の人と結果を比べましょう。自分とは違う案でしたか?
チャレンジ1の解答
x[2:4]b c d 6.2 7.1 4.8x[-c(1,5)]b c d 6.2 7.1 4.8x[c(2,3,4)]b c d 6.2 7.1 4.8
名前で部分集合を作る
要素番号で抜き出す代わりに、名前で要素を抽出することもできます。
x <- c(a=5.4, b=6.2, c=7.1, d=4.8, e=7.5) # ベクトルを'その場で'名づけることができます
x[c("a", "c")]
a c
5.4 7.1
オブジェクトの部分集合を作るには、この方法の方が確実です:要素の場所は、 部分集合の演算子を繋いで使うことでよく変わるのですが、 名前は絶対に変わりません。
他の論理演算子を使って部分集合を作る
どんな論理ベクトルでも部分集合を作ることができます:
x[c(FALSE, FALSE, TRUE, FALSE, TRUE)]
c e
7.1 7.5
比較演算子(例えば、 >、<、 ==)は、その結果が論理ベクトルになるので、
簡潔にベクトルの部分集合を作ることができます。
つまり、以下の宣言は、前と同じ結果を返します。
x[x > 7]
c e
7.1 7.5
分割すると、この宣言は最初に x>7 を計算し、論理ベクトル
c(FALSE, FALSE, TRUE, FALSE, TRUE) を作ります。それから、
TRUE の値に対応する要素を x から選択しています。
名前で特定するという既出の方法を真似するため、 == を使うこともできます。
(比較には、 = ではなく、 == を使わないといけません):
x[names(x) == "a"]
a
5.4
ヒント:論理条件を組み合わせる
複数の論理基準を組み合わせたい場合はよくあります。 例えば、アジアまたは ヨーロッパに位置し、なおかつ ある一定の範囲の平均余命 の国を見つけたいとします。 Rにが論理ベクトルを複数組み合わせる演算子があります:
&、「論理積」演算子:もし左と右の両方がTRUEであれば、TRUE|、「論理和」 演算子:もし左と右のどちらか(または両方)がTRUEであれば、TRUE
&及び|の代わりに、&&及び||を見かけることもあるでしょう。 この二重になっている演算子は、それぞれのベクトルの最初の要素だけを見て、残りを無視するものです。 一般的に、この二重になっている演算子はデータ分析では使わずに、 プログラミングの際に(つまり、ある宣言を実行するかどうかを決める際に) 使うことをおすすめします。
!、「論理否定」演算子:TRUEをFALSEに、FALSEをTRUEに変換します。 否定できるのは、一つの論理条件(例!TRUEがFALSEへ) または、条件のベクトル全体(例!c(TRUE, FALSE)が、c(FALSE, TRUE)へ)です。加えて、
all関数(ベクトルの全ての要素がTRUEである場合、TRUEを返す)及びany関数(ベクトルのうち最低1つ、TRUEがある場合、TRUEを返す)を使って ひとつのベクトルの中にある要素を比較することもできます。
チャレンジ2
以下のコードがあるとします:
x <- c(5.4, 6.2, 7.1, 4.8, 7.5) names(x) <- c('a', 'b', 'c', 'd', 'e') print(x)a b c d e 5.4 6.2 7.1 4.8 7.54よりも大きく7より小さいxの値を返す部分集合を作るコマンドを書きましょう。
チャレンジ2の解答
x_subset <- x[x<7 & x>4] print(x_subset)a b d 5.4 6.2 4.8
ヒント:同じ名前がある場合
ベクトルの中の要素に、同じ名前を持つものがあるかもしれないということを知っておく必要があります。 (データフレームでは、— Rは避けようとしますが — 列に同じ名前を付けることもできます。 一方で、行の名前は全て違う必要があります) これらの例を考えてみましょう:
x <- 1:3 x[1] 1 2 3names(x) <- c('a', 'a', 'a') xa a a 1 2 3x['a'] # 最初の値しか返さないa 1x[names(x) == 'a'] # 3つ全ての値を返すa a a 1 2 3
ヒント:演算子についてのヘルプを見る
演算子を引用符で囲むことで、演算子についてのヘルプを検索できることを覚えておきましょう:
help("%in%")または?"%in%".
名前のある要素を飛ばす
名前のある要素を飛ばしたり削除したりすることは少しだけ難しくなります。もし、ある文字列にマイナス記号を付けて飛ばそうとすると、Rは文字列にマイナス記号を付ける方法を知らないと(若干控えめに)抗議するでしょう:
x <- c(a=5.4, b=6.2, c=7.1, d=4.8, e=7.5) # まず、ベクトルにその場で名前を付けることから始めます
x[-"a"]
Error in -"a": invalid argument to unary operator
でも、!= (不等号)演算子を使えば、やってもらいたかったことをしてくれる論理ベクトルが作れます:
x[names(x) != "a"]
b c d e
6.2 7.1 4.8 7.5
複数の名前のある要素番号を飛ばすことは、少しですが、さらに難しくなります。"a" と"c" の要素を削除したいとき、以下を試したとしましょう:
x[names(x)!=c("a","c")]
Warning in names(x) != c("a", "c"): longer object length is not a multiple
of shorter object length
b c d e
6.2 7.1 4.8 7.5
Rは 何か をしたのですが、私達が注目しなければならない警告も出しました。結果としては、どうやら 間違った回答 が帰ってきたみたいです("c" の要素が、ベクトルに含まれています)!
ではいったい、 != は、ここで実際に何をしたのでしょう。これは素晴らしい質問です。
再利用
このコードの比較する部分を見てみましょう:
names(x) != c("a", "c")
Warning in names(x) != c("a", "c"): longer object length is not a multiple
of shorter object length
[1] FALSE TRUE TRUE TRUE TRUE
Rは、names(x)[3] != "c" が明らかに間違いであるときに、このベクトルの3番目の要素をなぜTRUE にしたのでしょうか。
!= を使うとき、Rは左側の引数のそれぞれの要素を右側のそれぞれの要素と比較しようとします。
違う長さのベクトルを比較しようとすると、何が起こるのでしょう?
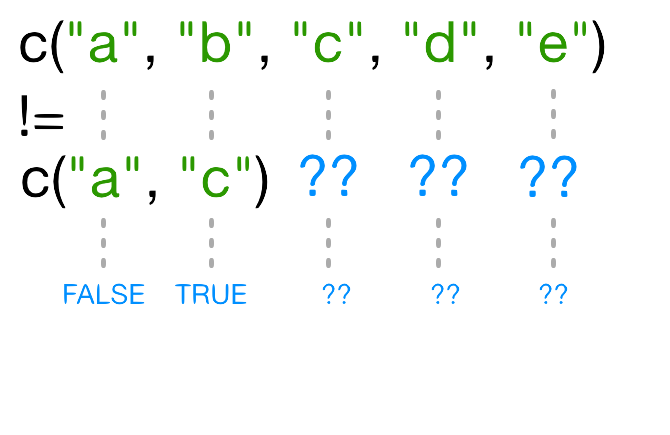
もし、もう一つのベクトルよりも短いベクトルがあったとき、そのベクトルは再利用されます:
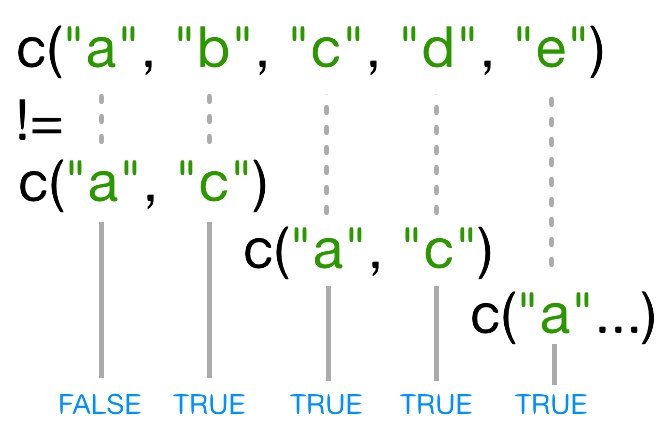
この場合、Rは c("a", "c") を names(x) に合わせるのに必要な分だけ繰り返します。つまり、c("a","c","a","c","a")となります。
再利用された"a" は、 names(x) の3番目の要素と一致しないため、 != の値は、TRUE なのです。
この場合、長い方のベクトルの長さ(5)は、短い方のベクトルの長さ(2)と一致しないので、Rは、警告メッセージを出力しました。もしも運悪くnames(x) が6つの要素を持っていた場合、Rは警告せずに 間違った(意図していなかった)ことを行っていたでしょう。この再利用のルールは、見つけるのがとても難しく、とらえがたいバグをもたらすことがあります!
Rに本当にやってもらいたいこと(左の引数の それぞれの 要素を、右の引数の要素の 全て にマッチさせること)をしてもらうには、 %in% 演算子を使う必要があります。%in% 演算子は、左の引数のそれぞれの要素、ここでは x の名前にひとつずつ 「この要素は、2番目の引数にあるかな」と尋ねていきます。ここで、値を 除く ため、「中にある(in)」を「中にない(not in)」に変える ! 演算子が必要です。
x[! names(x) %in% c("a","c") ]
b d e
6.2 4.8 7.5
チャレンジ3
データ分析をするにあたって、リスト内にある要素をベクトルの中から選択するのは よくあることです。例えば、gapminderのデータセットには、
国(country)及び大陸(continent)変数があるけれども、これら2つの目盛りの間 をつなぐ情報はありません。例えば東南アジアの情報を引き出したい場合、 全ての東南アジアの国をTRUEとし、その他をFALSEとする論理ベクトルを作る処理を どのように構築するのでしょう?次のようなデータを持っているとします:
seAsia <- c("Myanmar","Thailand","Cambodia","Vietnam","Laos") ## エピソード2でダウンロードしたgapminderのデータを読み込む gapminder <- read.csv("data/gapminder_data.csv", header=TRUE) ## `country` 列をデータフレームから読み込む(これを後で見ます) ## 順序なし因子を文字列へ変換します ## すると、繰り返していない要素だけを得られます countries <- unique(as.character(gapminder$country))警告が出てくる、間違った方法(
==のみを使う)、 粗削りな方法(論理演算子==及び|を使う)、 洗練された方法(%in%を使う)があります。 これら3つの方法それぞれの例を考え、それぞれがどう動く(動かない)か説明してください。チャレンジ3の解答
- この問題に対する誤った 方法は、
countries==seAsiaです。 これには、警告("In countries == seAsia : longer object length is not a multiple of shorter object length")が出ると共に、 誤った回答(全てがFALSEの値を持つベクトル)をもたらします。なぜなら、seAsiaの再利用された値のどれも、countryの値と正しく一致する並びになっていないからです。- この問題に対する粗削りな (でも技術的には合っている)方法は、
(countries=="Myanmar" | countries=="Thailand" | countries=="Cambodia" | countries == "Vietnam" | countries=="Laos")(または
countries==seAsia[1] | countries==seAsia[2] | ...)。 これは正しい値を返すのですが、この方法がどれだけ不格好であるか理解できれば上出来です (もっと長いリストから国を選ぶ場合は、この方法だったらどうなっていたでしょう?)。
- この問題に対する一番良い方法は、
countries %in% seAsiaで、 正しい回答でもあり、タイプする(読む)のも楽です。
特別な値を扱う
ある時点で、欠測値、無限値、未定義のデータを扱えないRの関数に出会うことでしょう。
データをフィルターするために使える特別な関数がいくつかあります:
is.naは、ベクトル、行列、データフレームで、 全てのNA(またはNaN)を含む位置を返します- これと同じことを
NaN及びInfにするのがis.nan及びis.infiniteです is.finiteは、ベクトル、行列、データフレームで、 全てのNA,NaNまたはInfを含まない位置を返しますna.omitは、ベクトルから欠損値をフィルターし、除きます
順序のない因子の部分集合を作る
これまで部分集合ベクトルを作る色々な方法をやってみましたが、 他のデータ構造の部分集合を作るにはどうすればいいでしょう。
順序なし因子の部分集合を作る方法は、ベクトルの部分集合を作る方法と同じです。
f <- factor(c("a", "a", "b", "c", "c", "d"))
f[f == "a"]
[1] a a
Levels: a b c d
f[f %in% c("b", "c")]
[1] b c c
Levels: a b c d
f[1:3]
[1] a a b
Levels: a b c d
要素を飛ばし、その順序なし因子に該当カテゴリーが存在しない場合であっても、水準は削除されません:
f[-3]
[1] a a c c d
Levels: a b c d
行列の部分周到を作る
行列も [ 関数を使うことで部分集合を作ることができます。この場合、
2つの引数があります。最初の引数は適応する行を、2番目の引数は適応する列を指します:
set.seed(1)
m <- matrix(rnorm(6*4), ncol=4, nrow=6)
m[3:4, c(3,1)]
[,1] [,2]
[1,] 1.12493092 -0.8356286
[2,] -0.04493361 1.5952808
それぞれ全ての列または行を取ってくるためには、最初または2番目の引数を空のままにしておきましょう:
m[, c(3,4)]
[,1] [,2]
[1,] -0.62124058 0.82122120
[2,] -2.21469989 0.59390132
[3,] 1.12493092 0.91897737
[4,] -0.04493361 0.78213630
[5,] -0.01619026 0.07456498
[6,] 0.94383621 -1.98935170
1つの列または行にアクセスした場合、Rは結果を自動的にベクトルに変換します:
m[3,]
[1] -0.8356286 0.5757814 1.1249309 0.9189774
もし、アウトプットを行列のままにしておきたいなら、3番目の 因数、
drop = FALSE が必要です:
m[3, , drop=FALSE]
[,1] [,2] [,3] [,4]
[1,] -0.8356286 0.5757814 1.124931 0.9189774
ベクトルと違って、行列の外の行や列にアクセスしようとすると、Rはエラーを返します:
m[, c(3,6)]
Error in m[, c(3, 6)]: subscript out of bounds
ヒント:高次元列
多次元列を扱う際、
[のそれぞれの引数は、次元に対応しています。 例えば、3次元列は、最初の3つの引数が、行、列、次元の深さに対応してます。
行列はベクトルなので、1つの引数だけを使って部分集合を作ることもできます:
m[5]
[1] 0.3295078
これは、普段使うには役に立たず、読むときにも混乱を招きます。ですが、行列は 列順序(column-major format) で デフォルト配置されるということを覚えておくといいでしょう。つまり、ベクトルの要素は、列にある順番で配置されています。
matrix(1:6, nrow=2, ncol=3)
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
もし、行列を行の順番で埋めていきたい場合は、 byrow=TRUE を使います:
matrix(1:6, nrow=2, ncol=3, byrow=TRUE)
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
行列もまた、行及び列の要素番号の代わりに、名前で部分集合を作ることができます。
チャレンジ4
以下のコードがあるとします:
m <- matrix(1:18, nrow=3, ncol=6) print(m)[,1] [,2] [,3] [,4] [,5] [,6] [1,] 1 4 7 10 13 16 [2,] 2 5 8 11 14 17 [3,] 3 6 9 12 15 18
- 次のコマンドのうち、11と14を抜き出すことができるコマンドはどれでしょう?
A.
m[2,4,2,5]B.
m[2:5]C.
m[4:5,2]D.
m[2,c(4,5)]チャレンジ4の解答
D
リストの分部集合を作る
ここで新しい部分集合を作る演算子を紹介します。リストの部分集合を作る関数は3つあります。
原子ベクトルと行列について学んだ時に、既に見たものです: [ 、 [[ 、$
[ を使えばいつもリストが返ってきます。リストの 部分集合 を作りたいけれども、
要素を 抜き出したい わけではないときは、おそらく [ を使うことが多いでしょう。
xlist <- list(a = "Software Carpentry", b = 1:10, data = head(iris))
xlist[1]
$a
[1] "Software Carpentry"
これは、 1つの要素を持つリスト です。
[ を使って原子ベクトルを作ったのと全く同じ方法で、リストの要素から部分集合を作ることができます。
しかし、比較処理は反復的ではないため、使えません。比較処理は、リストのそれぞれの要素のデータ構造にある、個々の要素ではなく、
データ構造に条件付けをしようとするからです。
xlist[1:2]
$a
[1] "Software Carpentry"
$b
[1] 1 2 3 4 5 6 7 8 9 10
リストの個々の要素を抜き出すためには、二重角括弧 [[ を使う必要があります:
xlist[[1]]
[1] "Software Carpentry"
ここで結果がリストではなく、ベクトルとなっていることに気をつけましょう。
1つの要素を同時に抜き出すことはできません:
xlist[[1:2]]
Error in xlist[[1:2]]: subscript out of bounds
また、要素を飛ばすこともできません:
xlist[[-1]]
Error in xlist[[-1]]: attempt to select more than one element in get1index <real>
でも両方の部分集合の名前を使って、要素を抽出することはできます:
xlist[["a"]]
[1] "Software Carpentry"
$ 関数は、簡単に名前で要素を抽出できるものです。
xlist$data
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
チャレンジ5
以下のリストがあるとします:
xlist <- list(a = "Software Carpentry", b = 1:10, data = head(iris))リストとベクトルの部分集合を作る知識を使って、xlistから、数字の2を抜き出してみましょう。 ヒント:数字の2は、リスト「b」の中にあります。
チャレンジ5の解答
xlist$b[2][1] 2xlist[[2]][2][1] 2xlist[["b"]][2][1] 2
チャレンジ6
以下のような線形モデルあるとします:
mod <- aov(pop ~ lifeExp, data=gapminder)残差の自由度を抜き出してみましょう(ヒント:
attributes()が役立つはずです)チャレンジ6の解答
attributes(mod) ## `df.residual` は、`mod` の名前のひとつですmod$df.residual
データフレーム
データフレームの中身は実はリストなので、リストと同じようなルールがあてはまることを覚えておきましょう。 しかし、データフレームは2次元のオブジェクトでもあります。
1つの引数しかない [ は、リストと同じような働きがあり、それぞれのリストの要素が列に対応します。
その結果、返されるオブジェクトはデータフレームになります:
head(gapminder[3])
pop
1 8425333
2 9240934
3 10267083
4 11537966
5 13079460
6 14880372
同様に、 [[ は、 単一の列 を抜き出す働きをするものです:
head(gapminder[["lifeExp"]])
[1] 28.801 30.332 31.997 34.020 36.088 38.438
そして $ は、簡単に列名で列を抽出できるものです:
head(gapminder$year)
[1] 1952 1957 1962 1967 1972 1977
2つの引数を使えば、 [ は、行列と同じような働きをします:
gapminder[1:3,]
country year pop continent lifeExp gdpPercap
1 Afghanistan 1952 8425333 Asia 28.801 779.4453
2 Afghanistan 1957 9240934 Asia 30.332 820.8530
3 Afghanistan 1962 10267083 Asia 31.997 853.1007
もし、1つの行を部分集合する場合、結果はデータフレームになります (理由は、要素には色々なデータ型が混ざっているからです):
gapminder[3,]
country year pop continent lifeExp gdpPercap
3 Afghanistan 1962 10267083 Asia 31.997 853.1007
しかし、1つの行についての結果は、ベクトルになります
(これは、3番目の引数を drop = FALSE とすれば変えられます)。
チャレンジ7
以下の一般的なデータフレームの部分集合を作る際のエラーを修正しましょう:
1957年に集められた観測値を抜き出す
gapminder[gapminder$year = 1957,]1から4を除く全ての列を抜き出す
gapminder[,-1:4]平均余命が80歳以上の行を抜き出す
gapminder[gapminder$lifeExp > 80]最初の行の4番目と5番目の列を抜き出す (
lifeExpとgdpPercap).gapminder[1, 4, 5]上級:2002年と2007年の情報を含む行を抜き出す
gapminder[gapminder$year == 2002 | 2007,]チャレンジ7の解答
以下の一般的なデータフレームの部分集合を作る際のエラーを修正しましょう:
- 1957年に集められた観測値を抜き出す
# gapminder[gapminder$year = 1957,] gapminder[gapminder$year == 1957,]
1から4を除く全ての列を抜き出す
# gapminder[,-1:4] gapminder[,-c(1:4)]平均余命が80歳以上の行を抜き出す
# gapminder[gapminder$lifeExp > 80] gapminder[gapminder$lifeExp > 80,]最初の行の4番目と5番目の列を抜き出す (
lifeExpとgdpPercap).# gapminder[1, 4, 5] gapminder[1, c(4, 5)]上級:2002年と2007年の情報を含む行を抜き出す
# gapminder[gapminder$year == 2002 | 2007,] gapminder[gapminder$year == 2002 | gapminder$year == 2007,] gapminder[gapminder$year %in% c(2002, 2007),]
チャレンジ8
なぜ、
gapminder[1:20]は、エラーを返すのでしょうか?gapminder[1:20, ]とどう違うのでしょう?新しく
gapminder_smallという、1から9の行だけを含むdata.frameを作ってください。 これは、1つまたは2つの手順でできます。チャレンジ8の解答
gapminderは、データフレームなので、2つの次元の部分集合を作る必要があります。gapminder[1:20, ]は、最初から20番目の行までについて全ての列を引き出します。gapminder_small <- gapminder[c(1:9, 19:23),]
まとめ
R のインデックスは 0 ではなく 1 から始まる。
[]を使用して個々の値にアクセス出来る。
[下の番号:上の番号]を使用してスライスされたデータにアクセス出来る。
[c(...)]を使用して任意のデータセットにアクセス出来る。論理演算や論理ベクターを使用してデータの部分集合にアクセス出来る。