tidyr を使用したデータフレームの操作
最終更新日:2024-11-22 | ページの編集
概要
質問
- データフレームのレイアウトをどのように変更できますか?
目的
- ’長い’データフレーム形式と’広い’データフレーム形式の概念を理解し、
tidyrを使ってそれらを変換できるようになる。
研究者はしばしば、データフレームの形式を「広い」レイアウトから「長い」レイアウトに変換したり、その逆を行ったりします。「長い」レイアウトまたは形式では以下のような特徴があります:
- 各列が変数
- 各行が観測値
純粋な「長い」形式では、通常、1列が観測値の変数であり、他の列がID変数です。
「広い」形式では、各行がサイト/被験者/患者を表し、同じ種類のデータを含む複数の観測変数があります。これには、時間経過での繰り返し観測や複数の変数の観測(またはその両方の混合)が含まれます。「広い」形式のほうがデータ入力が簡単である場合や、一部のアプリケーションが「広い」形式を好む場合があります。ただし、R
の多くの関数は「長い」形式のデータを想定して設計されています。このチュートリアルでは、元の形式に関係なく、データの形状を効率的に変換する方法を学びます。
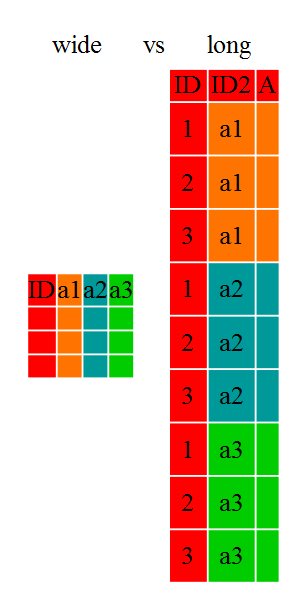
長いデータフレームと広いデータフレームのレイアウトは主に可読性に影響します。人間にとって「広い」形式は、形状のために画面上でより多くのデータを確認できるため、より直感的な場合があります。しかし、「長い」形式は機械可読性が高く、データベースの形式に近いです。データフレームのID変数はデータベースのフィールドに、観測変数はデータベースの値に似ています。
開始方法
まず、まだインストールしていない場合は以下を実行してください(前回のレッスンでdplyrをインストールした可能性があります):
R
#install.packages("tidyr")
#install.packages("dplyr")
パッケージをロードします:
R
library("tidyr")
library("dplyr")
まず、元のgapminderデータフレームの構造を見てみましょう:
R
str(gapminder)
出力
'data.frame': 1704 obs. of 6 variables:
$ country : chr "Afghanistan" "Afghanistan" "Afghanistan" "Afghanistan" ...
$ year : int 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 ...
$ pop : num 8425333 9240934 10267083 11537966 13079460 ...
$ continent: chr "Asia" "Asia" "Asia" "Asia" ...
$ lifeExp : num 28.8 30.3 32 34 36.1 ...
$ gdpPercap: num 779 821 853 836 740 ...チャレンジ 1
gapminder
は純粋に「長い」形式、「広い」形式、または中間形式のどれですか?
元の gapminder
データフレームは中間形式です。純粋に「長い」形式ではなく、複数の観測変数
(pop、lifeExp、gdpPercap)を持っています。
時々、gapminderデータセットのように、複数種類の観測データを持つことがあります。これは純粋な「長い」形式と「広い」形式の間のどこかに位置します。このデータセットには3つの「ID変数」
(continent、country、year)と3つの「観測変数」(pop、lifeExp、gdpPercap)があります。この中間形式は、すべての観測値を1列にする純粋に「長い」形式ではありませんが、それでも好まれる場合があります。これは、すべての観測変数が異なる単位を持っているためです。
多くのRの関数は「長い」形式を想定していますが、注意: 一部のプロット関数は「広い」形式のほうがうまく機能する場合があります。
pivot_longer() を使用して「広い」形式から「長い」形式に変換
これまで、適切にフォーマットされた元のgapminderデータセットを使用していましたが、「実際」のデータ(例:自分の研究データ)は通常、これほど整理されていません。ここでは、「広い」形式のgapminderデータセットを使用します。
「広い」形式の
gapminderデータをこちらのcsvファイルのリンクからダウンロードして、dataフォルダに保存してください。
データファイルをロードして確認しましょう。注意:continentとcountry列をファクターにしたくないため、read.csv()のstringsAsFactors引数を使用して無効にします。
R
gap_wide <- read.csv("data/gapminder_wide.csv", stringsAsFactors = FALSE)
str(gap_wide)
出力
'data.frame': 142 obs. of 38 variables:
$ continent : chr "Africa" "Africa" "Africa" "Africa" ...
$ country : chr "Algeria" "Angola" "Benin" "Botswana" ...
$ gdpPercap_1952: num 2449 3521 1063 851 543 ...
$ gdpPercap_1957: num 3014 3828 960 918 617 ...
$ gdpPercap_1962: num 2551 4269 949 984 723 ...
$ gdpPercap_1967: num 3247 5523 1036 1215 795 ...
$ gdpPercap_1972: num 4183 5473 1086 2264 855 ...
$ gdpPercap_1977: num 4910 3009 1029 3215 743 ...
$ gdpPercap_1982: num 5745 2757 1278 4551 807 ...
$ gdpPercap_1987: num 5681 2430 1226 6206 912 ...
$ gdpPercap_1992: num 5023 2628 1191 7954 932 ...
$ gdpPercap_1997: num 4797 2277 1233 8647 946 ...
$ gdpPercap_2002: num 5288 2773 1373 11004 1038 ...
$ gdpPercap_2007: num 6223 4797 1441 12570 1217 ...
$ lifeExp_1952 : num 43.1 30 38.2 47.6 32 ...
$ lifeExp_1957 : num 45.7 32 40.4 49.6 34.9 ...
$ lifeExp_1962 : num 48.3 34 42.6 51.5 37.8 ...
$ lifeExp_1967 : num 51.4 36 44.9 53.3 40.7 ...
$ lifeExp_1972 : num 54.5 37.9 47 56 43.6 ...
$ lifeExp_1977 : num 58 39.5 49.2 59.3 46.1 ...
$ lifeExp_1982 : num 61.4 39.9 50.9 61.5 48.1 ...
$ lifeExp_1987 : num 65.8 39.9 52.3 63.6 49.6 ...
$ lifeExp_1992 : num 67.7 40.6 53.9 62.7 50.3 ...
$ lifeExp_1997 : num 69.2 41 54.8 52.6 50.3 ...
$ lifeExp_2002 : num 71 41 54.4 46.6 50.6 ...
$ lifeExp_2007 : num 72.3 42.7 56.7 50.7 52.3 ...
$ pop_1952 : num 9279525 4232095 1738315 442308 4469979 ...
$ pop_1957 : num 10270856 4561361 1925173 474639 4713416 ...
$ pop_1962 : num 11000948 4826015 2151895 512764 4919632 ...
$ pop_1967 : num 12760499 5247469 2427334 553541 5127935 ...
$ pop_1972 : num 14760787 5894858 2761407 619351 5433886 ...
$ pop_1977 : num 17152804 6162675 3168267 781472 5889574 ...
$ pop_1982 : num 20033753 7016384 3641603 970347 6634596 ...
$ pop_1987 : num 23254956 7874230 4243788 1151184 7586551 ...
$ pop_1992 : num 26298373 8735988 4981671 1342614 8878303 ...
$ pop_1997 : num 29072015 9875024 6066080 1536536 10352843 ...
$ pop_2002 : int 31287142 10866106 7026113 1630347 12251209 7021078 15929988 4048013 8835739 614382 ...
$ pop_2007 : int 33333216 12420476 8078314 1639131 14326203 8390505 17696293 4369038 10238807 710960 ...
この非常に「広い」データフレームを「長い」レイアウトに戻すには、tidyrパッケージのpivot関数の1つであるpivot_longer()を使用します。この関数は、行数を増やして列数を減らすことによってデータセットを「長い」形式に変換します。
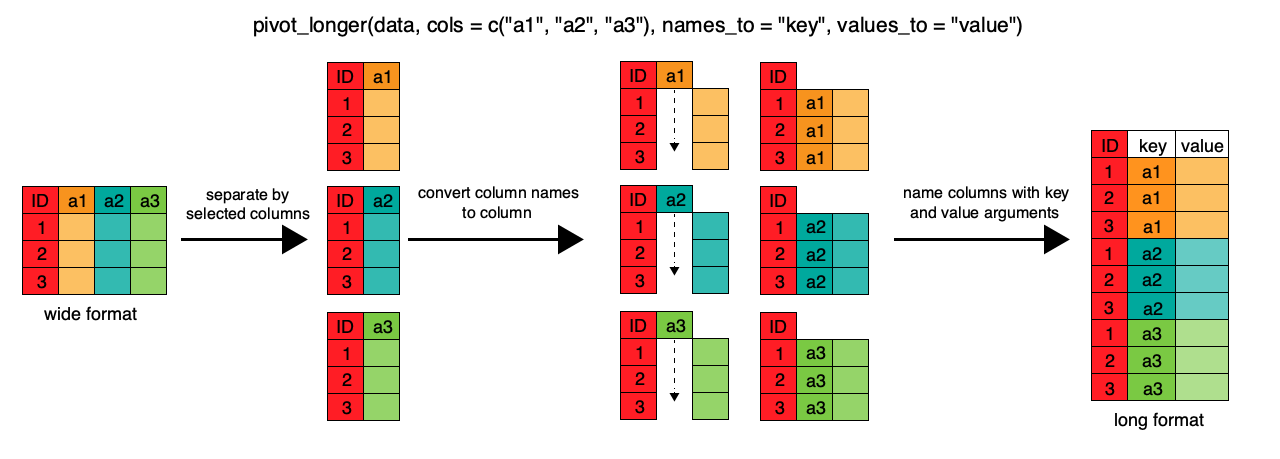
R
gap_long <- gap_wide %>%
pivot_longer(
cols = c(starts_with('pop'), starts_with('lifeExp'), starts_with('gdpPercap')),
names_to = "obstype_year", values_to = "obs_values"
)
str(gap_long)
出力
tibble [5,112 × 4] (S3: tbl_df/tbl/data.frame)
$ continent : chr [1:5112] "Africa" "Africa" "Africa" "Africa" ...
$ country : chr [1:5112] "Algeria" "Algeria" "Algeria" "Algeria" ...
$ obstype_year: chr [1:5112] "pop_1952" "pop_1957" "pop_1962" "pop_1967" ...
$ obs_values : num [1:5112] 9279525 10270856 11000948 12760499 14760787 ...ここでは、前回のdplyrレッスンで学んだパイピング構文を使用しています。実際、tidyrとdplyrの関数を組み合わせて使用することが可能です。
次に、separate()関数を使用して、文字列を複数の変数に分割します:
R
gap_long <- gap_long %>% separate(obstype_year, into = c('obs_type', 'year'), sep = "_")
gap_long$year <- as.integer(gap_long$year)
チャレンジ 2
gap_long を使用して、大陸ごとの平均寿命、人口、GDP per
capitaを計算してください。 ヒント:
dplyrレッスンで学んだgroup_by()とsummarize()関数を使用してください。
R
gap_long %>% group_by(continent, obs_type) %>%
summarize(means=mean(obs_values))
出力
`summarise()` has grouped output by 'continent'. You can override using the
`.groups` argument.出力
# A tibble: 15 × 3
# Groups: continent [5]
continent obs_type means
<chr> <chr> <dbl>
1 Africa gdpPercap 2194.
2 Africa lifeExp 48.9
3 Africa pop 9916003.
4 Americas gdpPercap 7136.
5 Americas lifeExp 64.7
6 Americas pop 24504795.
7 Asia gdpPercap 7902.
8 Asia lifeExp 60.1
9 Asia pop 77038722.
10 Europe gdpPercap 14469.
11 Europe lifeExp 71.9
12 Europe pop 17169765.
13 Oceania gdpPercap 18622.
14 Oceania lifeExp 74.3
15 Oceania pop 8874672. pivot_wider() を使用して長い形式から中間形式へ
作業を確認するのは常に良いことです。それでは、2つ目の
pivot 関数である pivot_wider()
を使用して、観測変数を再び「広げ」てみましょう。pivot_wider()
は pivot_longer()
の逆で、データセットの列数を増やし、行数を減らすことでデータを「広い」形式に変換します。pivot_wider()
を使用して、gap_long
を元の中間形式または最も広い形式に変換できます。まずは中間形式から始めましょう。
pivot_wider() 関数には names_from と
values_from 引数があります。
names_from
には、広げたデータフレームで新しい出力列としてピボットされる列名を指定します。対応する値は、values_from
引数で指定された列から追加されます。
R
gap_normal <- gap_long %>%
pivot_wider(names_from = obs_type, values_from = obs_values)
dim(gap_normal)
出力
[1] 1704 6R
dim(gapminder)
出力
[1] 1704 6R
names(gap_normal)
出力
[1] "continent" "country" "year" "pop" "lifeExp" "gdpPercap"R
names(gapminder)
出力
[1] "country" "year" "pop" "continent" "lifeExp" "gdpPercap"これで、元のgapminderと同じ次元を持つ中間形式のデータフレームgap_normalができましたが、変数の順序が異なります。これを修正してから、all.equal()
でチェックします。
R
gap_normal <- gap_normal[, names(gapminder)]
all.equal(gap_normal, gapminder)
出力
[1] "Attributes: < Component \"class\": Lengths (3, 1) differ (string compare on first 1) >"
[2] "Attributes: < Component \"class\": 1 string mismatch >"
[3] "Component \"country\": 1704 string mismatches"
[4] "Component \"pop\": Mean relative difference: 1.634504"
[5] "Component \"continent\": 1212 string mismatches"
[6] "Component \"lifeExp\": Mean relative difference: 0.203822"
[7] "Component \"gdpPercap\": Mean relative difference: 1.162302" R
head(gap_normal)
出力
# A tibble: 6 × 6
country year pop continent lifeExp gdpPercap
<chr> <int> <dbl> <chr> <dbl> <dbl>
1 Algeria 1952 9279525 Africa 43.1 2449.
2 Algeria 1957 10270856 Africa 45.7 3014.
3 Algeria 1962 11000948 Africa 48.3 2551.
4 Algeria 1967 12760499 Africa 51.4 3247.
5 Algeria 1972 14760787 Africa 54.5 4183.
6 Algeria 1977 17152804 Africa 58.0 4910.R
head(gapminder)
出力
country year pop continent lifeExp gdpPercap
1 Afghanistan 1952 8425333 Asia 28.801 779.4453
2 Afghanistan 1957 9240934 Asia 30.332 820.8530
3 Afghanistan 1962 10267083 Asia 31.997 853.1007
4 Afghanistan 1967 11537966 Asia 34.020 836.1971
5 Afghanistan 1972 13079460 Asia 36.088 739.9811
6 Afghanistan 1977 14880372 Asia 38.438 786.1134ほとんど完成ですが、元のデータはcountryとyearでソートされています。
R
gap_normal <- gap_normal %>% arrange(country, year)
all.equal(gap_normal, gapminder)
出力
[1] "Attributes: < Component \"class\": Lengths (3, 1) differ (string compare on first 1) >"
[2] "Attributes: < Component \"class\": 1 string mismatch >" 素晴らしいですね!最も長い形式から中間形式に戻り、コードにエラーがないことを確認できました。
次に、最も長い形式から最も広い形式まで変換してみましょう。この広い形式では、countryとcontinentをID変数として保持し、3つのメトリクス(pop、lifeExp、gdpPercap)と時間(year)にわたる観測値をピボットします。まず、新しい変数(時間*メトリクスの組み合わせ)に適切なラベルを作成し、ID変数を統合してgap_wideを定義しやすくします。
R
gap_temp <- gap_long %>% unite(var_ID, continent, country, sep = "_")
str(gap_temp)
出力
tibble [5,112 × 4] (S3: tbl_df/tbl/data.frame)
$ var_ID : chr [1:5112] "Africa_Algeria" "Africa_Algeria" "Africa_Algeria" "Africa_Algeria" ...
$ obs_type : chr [1:5112] "pop" "pop" "pop" "pop" ...
$ year : int [1:5112] 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 ...
$ obs_values: num [1:5112] 9279525 10270856 11000948 12760499 14760787 ...R
gap_temp <- gap_long %>%
unite(ID_var, continent, country, sep = "_") %>%
unite(var_names, obs_type, year, sep = "_")
str(gap_temp)
出力
tibble [5,112 × 3] (S3: tbl_df/tbl/data.frame)
$ ID_var : chr [1:5112] "Africa_Algeria" "Africa_Algeria" "Africa_Algeria" "Africa_Algeria" ...
$ var_names : chr [1:5112] "pop_1952" "pop_1957" "pop_1962" "pop_1967" ...
$ obs_values: num [1:5112] 9279525 10270856 11000948 12760499 14760787 ...unite()
を使用して、continent、country
を統合した単一のID変数を作成し、変数名を定義しました。これで、pivot_wider()
に渡す準備が整いました。
R
gap_wide_new <- gap_long %>%
unite(ID_var, continent, country, sep = "_") %>%
unite(var_names, obs_type, year, sep = "_") %>%
pivot_wider(names_from = var_names, values_from = obs_values)
str(gap_wide_new)
出力
tibble [142 × 37] (S3: tbl_df/tbl/data.frame)
$ ID_var : chr [1:142] "Africa_Algeria" "Africa_Angola" "Africa_Benin" "Africa_Botswana" ...
$ pop_1952 : num [1:142] 9279525 4232095 1738315 442308 4469979 ...
$ pop_1957 : num [1:142] 10270856 4561361 1925173 474639 4713416 ...
$ pop_1962 : num [1:142] 11000948 4826015 2151895 512764 4919632 ...
$ pop_1967 : num [1:142] 12760499 5247469 2427334 553541 5127935 ...
$ pop_1972 : num [1:142] 14760787 5894858 2761407 619351 5433886 ...
$ pop_1977 : num [1:142] 17152804 6162675 3168267 781472 5889574 ...
$ pop_1982 : num [1:142] 20033753 7016384 3641603 970347 6634596 ...
$ pop_1987 : num [1:142] 23254956 7874230 4243788 1151184 7586551 ...
$ pop_1992 : num [1:142] 26298373 8735988 4981671 1342614 8878303 ...
$ pop_1997 : num [1:142] 29072015 9875024 6066080 1536536 10352843 ...
$ pop_2002 : num [1:142] 31287142 10866106 7026113 1630347 12251209 ...
$ pop_2007 : num [1:142] 33333216 12420476 8078314 1639131 14326203 ...
$ lifeExp_1952 : num [1:142] 43.1 30 38.2 47.6 32 ...
$ lifeExp_1957 : num [1:142] 45.7 32 40.4 49.6 34.9 ...
$ lifeExp_1962 : num [1:142] 48.3 34 42.6 51.5 37.8 ...
$ lifeExp_1967 : num [1:142] 51.4 36 44.9 53.3 40.7 ...
$ lifeExp_1972 : num [1:142] 54.5 37.9 47 56 43.6 ...
$ lifeExp_1977 : num [1:142] 58 39.5 49.2 59.3 46.1 ...
$ lifeExp_1982 : num [1:142] 61.4 39.9 50.9 61.5 48.1 ...
$ lifeExp_1987 : num [1:142] 65.8 39.9 52.3 63.6 49.6 ...
$ lifeExp_1992 : num [1:142] 67.7 40.6 53.9 62.7 50.3 ...
$ lifeExp_1997 : num [1:142] 69.2 41 54.8 52.6 50.3 ...
$ lifeExp_2002 : num [1:142] 71 41 54.4 46.6 50.6 ...
$ lifeExp_2007 : num [1:142] 72.3 42.7 56.7 50.7 52.3 ...
$ gdpPercap_1952: num [1:142] 2449 3521 1063 851 543 ...
$ gdpPercap_1957: num [1:142] 3014 3828 960 918 617 ...
$ gdpPercap_1962: num [1:142] 2551 4269 949 984 723 ...
$ gdpPercap_1967: num [1:142] 3247 5523 1036 1215 795 ...
$ gdpPercap_1972: num [1:142] 4183 5473 1086 2264 855 ...
$ gdpPercap_1977: num [1:142] 4910 3009 1029 3215 743 ...
$ gdpPercap_1982: num [1:142] 5745 2757 1278 4551 807 ...
$ gdpPercap_1987: num [1:142] 5681 2430 1226 6206 912 ...
$ gdpPercap_1992: num [1:142] 5023 2628 1191 7954 932 ...
$ gdpPercap_1997: num [1:142] 4797 2277 1233 8647 946 ...
$ gdpPercap_2002: num [1:142] 5288 2773 1373 11004 1038 ...
$ gdpPercap_2007: num [1:142] 6223 4797 1441 12570 1217 ...チャレンジ 3
これをさらに一歩進めて、国、年、3つのメトリクスに基づいてピボットすることで、gap_ludicrously_wide
フォーマットデータを作成してください。 ヒント:
この新しいデータフレームには5行しかないはずです。
R
gap_ludicrously_wide <- gap_long %>%
unite(var_names, obs_type, year, country, sep = "_") %>%
pivot_wider(names_from = var_names, values_from = obs_values)
これで素晴らしい「広い」形式のデータフレームができましたが、ID_var
をより使いやすくするために、separate()
を使用して2つの変数に分割します。
R
gap_wide_betterID <- separate(gap_wide_new, ID_var, c("continent", "country"), sep="_")
gap_wide_betterID <- gap_long %>%
unite(ID_var, continent, country, sep = "_") %>%
unite(var_names, obs_type, year, sep = "_") %>%
pivot_wider(names_from = var_names, values_from = obs_values) %>%
separate(ID_var, c("continent","country"), sep = "_")
str(gap_wide_betterID)
出力
tibble [142 × 38] (S3: tbl_df/tbl/data.frame)
$ continent : chr [1:142] "Africa" "Africa" "Africa" "Africa" ...
$ country : chr [1:142] "Algeria" "Angola" "Benin" "Botswana" ...
$ pop_1952 : num [1:142] 9279525 4232095 1738315 442308 4469979 ...
$ pop_1957 : num [1:142] 10270856 4561361 1925173 474639 4713416 ...
$ pop_1962 : num [1:142] 11000948 4826015 2151895 512764 4919632 ...
$ pop_1967 : num [1:142] 12760499 5247469 2427334 553541 5127935 ...
$ pop_1972 : num [1:142] 14760787 5894858 2761407 619351 5433886 ...
$ pop_1977 : num [1:142] 17152804 6162675 3168267 781472 5889574 ...
$ pop_1982 : num [1:142] 20033753 7016384 3641603 970347 6634596 ...
$ pop_1987 : num [1:142] 23254956 7874230 4243788 1151184 7586551 ...
$ pop_1992 : num [1:142] 26298373 8735988 4981671 1342614 8878303 ...
$ pop_1997 : num [1:142] 29072015 9875024 6066080 1536536 10352843 ...
$ pop_2002 : num [1:142] 31287142 10866106 7026113 1630347 12251209 ...
$ pop_2007 : num [1:142] 33333216 12420476 8078314 1639131 14326203 ...
$ lifeExp_1952 : num [1:142] 43.1 30 38.2 47.6 32 ...
$ lifeExp_1957 : num [1:142] 45.7 32 40.4 49.6 34.9 ...
$ lifeExp_1962 : num [1:142] 48.3 34 42.6 51.5 37.8 ...
$ lifeExp_1967 : num [1:142] 51.4 36 44.9 53.3 40.7 ...
$ lifeExp_1972 : num [1:142] 54.5 37.9 47 56 43.6 ...
$ lifeExp_1977 : num [1:142] 58 39.5 49.2 59.3 46.1 ...
$ lifeExp_1982 : num [1:142] 61.4 39.9 50.9 61.5 48.1 ...
$ lifeExp_1987 : num [1:142] 65.8 39.9 52.3 63.6 49.6 ...
$ lifeExp_1992 : num [1:142] 67.7 40.6 53.9 62.7 50.3 ...
$ lifeExp_1997 : num [1:142] 69.2 41 54.8 52.6 50.3 ...
$ lifeExp_2002 : num [1:142] 71 41 54.4 46.6 50.6 ...
$ lifeExp_2007 : num [1:142] 72.3 42.7 56.7 50.7 52.3 ...
$ gdpPercap_1952: num [1:142] 2449 3521 1063 851 543 ...
$ gdpPercap_1957: num [1:142] 3014 3828 960 918 617 ...
$ gdpPercap_1962: num [1:142] 2551 4269 949 984 723 ...
$ gdpPercap_1967: num [1:142] 3247 5523 1036 1215 795 ...
$ gdpPercap_1972: num [1:142] 4183 5473 1086 2264 855 ...
$ gdpPercap_1977: num [1:142] 4910 3009 1029 3215 743 ...
$ gdpPercap_1982: num [1:142] 5745 2757 1278 4551 807 ...
$ gdpPercap_1987: num [1:142] 5681 2430 1226 6206 912 ...
$ gdpPercap_1992: num [1:142] 5023 2628 1191 7954 932 ...
$ gdpPercap_1997: num [1:142] 4797 2277 1233 8647 946 ...
$ gdpPercap_2002: num [1:142] 5288 2773 1373 11004 1038 ...
$ gdpPercap_2007: num [1:142] 6223 4797 1441 12570 1217 ...R
all.equal(gap_wide, gap_wide_betterID)
出力
[1] "Names: 24 string mismatches"
[2] "Attributes: < Component \"class\": Lengths (1, 3) differ (string compare on first 1) >"
[3] "Attributes: < Component \"class\": 1 string mismatch >"
[4] "Component 3: Mean relative difference: 4549.106"
[5] "Component 4: Mean relative difference: 4363.185"
[6] "Component 5: Mean relative difference: 4320.163"
[7] "Component 6: Mean relative difference: 4130.972"
[8] "Component 7: Mean relative difference: 3719.779"
[9] "Component 8: Mean relative difference: 3783.459"
[10] "Component 9: Mean relative difference: 4016.515"
[11] "Component 10: Mean relative difference: 4180.611"
[12] "Component 11: Mean relative difference: 4410.404"
[13] "Component 12: Mean relative difference: 4271.686"
[14] "Component 13: Mean relative difference: 4179.099"
[15] "Component 14: Mean relative difference: 3767.917"
[16] "Component 27: Mean relative difference: 0.9997802"
[17] "Component 28: Mean relative difference: 0.9997709"
[18] "Component 29: Mean relative difference: 0.9997686"
[19] "Component 30: Mean relative difference: 0.999758"
[20] "Component 31: Mean relative difference: 0.9997312"
[21] "Component 32: Mean relative difference: 0.9997358"
[22] "Component 33: Mean relative difference: 0.9997511"
[23] "Component 34: Mean relative difference: 0.9997609"
[24] "Component 35: Mean relative difference: 0.9997733"
[25] "Component 36: Mean relative difference: 0.999766"
[26] "Component 37: Mean relative difference: 0.9997608"
[27] "Component 38: Mean relative difference: 0.9997347" 行って戻るプロセスが完了しました!
その他の素晴らしいリソース
- R for Data Science (オンライン書籍)
- データ整形チートシート (PDFファイル)
- tidyr 入門 (オンラインドキュメント)
- R と RStudio を使用したデータ整形 (オンラインビデオ)
まとめ
- データフレームのレイアウトを変更するために
tidyrパッケージを使用する。 -
pivot_longer()を使用して「広い」レイアウトから「長い」レイアウトに変換する。 -
pivot_wider()を使用して「長い」レイアウトから「広い」レイアウトに変換する。