データの部分集合化
最終更新日:2024-11-22 | ページの編集
概要
質問
- R でデータの部分集合をどのように扱うことができますか?
目的
- ベクトル、因子、行列、リスト、データフレームの部分集合化を学ぶ
- インデックス、名前、比較演算を使って個々の要素や複数の要素を抽出する方法を理解する
- さまざまなデータ構造から要素をスキップまたは削除する方法を習得する
R には強力な部分集合化のための演算子が数多く用意されています。それらを習得することで、あらゆる種類のデータセットで複雑な操作を簡単に行えるようになります。
あらゆる種類のオブジェクトを部分集合化するために 6 つの異なる方法があり、データ構造ごとに 3 種類の部分集合化演算子があります。
では、R の基本となる数値ベクトルを使って始めましょう。
R
x <- c(5.4, 6.2, 7.1, 4.8, 7.5)
names(x) <- c('a', 'b', 'c', 'd', 'e')
x
出力
a b c d e
5.4 6.2 7.1 4.8 7.5 アトミックベクトル
R では、文字列、数値、または論理値を含む単純なベクトルを アトミックベクトル と呼びます。これは、さらに単純化できないためです。
このようにダミーベクトルを作成しました。この中身をどのように取得するのでしょうか?
インデックスを使用した要素のアクセス
ベクトルの要素を抽出するには、対応するインデックスを指定します(1 から始まります):
R
x[1]
出力
a
5.4 R
x[4]
出力
d
4.8 角括弧 [] 演算子は関数であり、ベクトルや行列に対して「n
番目の要素を取得する」という意味を持ちます。
複数の要素を一度に取得することもできます:
R
x[c(1, 3)]
出力
a c
5.4 7.1 またはベクトルの一部(スライス)を取得することも可能です:
R
x[1:4]
出力
a b c d
5.4 6.2 7.1 4.8 :
演算子は左の値から右の値までの数値のシーケンスを生成します。
R
1:4
出力
[1] 1 2 3 4R
c(1, 2, 3, 4)
出力
[1] 1 2 3 4同じ要素を複数回取得することもできます:
R
x[c(1,1,3)]
出力
a a c
5.4 5.4 7.1 ベクトルの長さを超えるインデックスを指定すると、R は欠損値を返します:
R
x[6]
出力
<NA>
NA これは NA を含む長さ 1 のベクトルであり、名前も
NA です。
0 番目の要素を要求すると、空のベクトルが返されます:
R
x[0]
出力
named numeric(0)R のベクトルの番号付けは 1 から始まる
多くのプログラミング言語(C や Python など)では、ベクトルの最初の要素のインデックスは 0 です。一方、R では最初の要素は 1 です。
要素のスキップと削除
ベクトルのインデックスに負の数を使用すると、指定した要素を除くすべての要素が返されます:
R
x[-2]
出力
a c d e
5.4 7.1 4.8 7.5 複数の要素をスキップすることも可能です:
R
x[c(-1, -5)] # または x[-c(1,5)]
出力
b c d
6.2 7.1 4.8 ヒント: 演算の順序
ベクトルの一部をスキップしようとすると、新しい人はよく間違えます。例えば:
R
x[-1:3]
このコードは次のようなエラーを返します:
エラー
Error in x[-1:3]: only 0's may be mixed with negative subscriptsこれは演算の順序が関係しています。:
は実際には関数であり、最初の引数を -1、2 番目の引数を
3
としてシーケンスを生成します:c(-1, 0, 1, 2, 3)。
正しい解決策は、この関数呼び出しを括弧で囲み、-
演算子を結果に適用することです:
R
x[-(1:3)]
出力
d e
4.8 7.5 ベクトルから要素を削除するには、結果を変数に再割り当てする必要があります:
R
x <- x[-4]
x
出力
a b c e
5.4 6.2 7.1 7.5 チャレンジ 1
次のコードが与えられた場合:
R
x <- c(5.4, 6.2, 7.1, 4.8, 7.5)
names(x) <- c('a', 'b', 'c', 'd', 'e')
print(x)
出力
a b c d e
5.4 6.2 7.1 4.8 7.5 次の出力を生成する少なくとも 2 つの異なるコマンドを考え出してください:
出力
b c d
6.2 7.1 4.8 2 つの異なるコマンドを見つけたら、隣の人と比較してみてください。異なる戦略を持っていましたか?
R
x[2:4]
出力
b c d
6.2 7.1 4.8 R
x[-c(1,5)]
出力
b c d
6.2 7.1 4.8 R
x[c(2,3,4)]
出力
b c d
6.2 7.1 4.8 名前によるサブセット
インデックスではなく名前を使って要素を抽出することができます:
R
x <- c(a=5.4, b=6.2, c=7.1, d=4.8, e=7.5) # ベクトルにその場で名前を付ける
x[c("a", "c")]
出力
a c
5.4 7.1 これは、オブジェクトをサブセットする際に、通常より信頼性の高い方法です。
サブセット操作を連続して行う場合、要素の位置が変わることがありますが、名前は常に変わりません!
他の論理演算を用いたサブセット
論理ベクトルを使ってサブセットを取ることもできます:
R
x[c(FALSE, FALSE, TRUE, FALSE, TRUE)]
出力
c e
7.1 7.5 比較演算子(例:>、<、==)は論理ベクトルを生成するため、それを使ってベクトルを簡潔にサブセットできます。以下のステートメントは、前の例と同じ結果を返します。
R
x[x > 7]
出力
c e
7.1 7.5 このステートメントを分解すると、まず x>7
が評価されて論理ベクトル c(FALSE, FALSE, TRUE, FALSE, TRUE)
が生成され、それに基づいて x の要素が選択されます。
名前によるインデックス操作を模倣するには、==
を使うことができます(比較には = ではなく ==
を使用する必要がある点に注意):
R
x[names(x) == "a"]
出力
a
5.4 ヒント: 複数の論理条件の結合
複数の論理条件を結合したい場合があります。たとえば、特定の範囲内の寿命を持つアジアまたはヨーロッパに位置するすべての国を見つけたいとします。このような場合、R では論理ベクトルを結合するための以下の演算子を使用できます:
-
&(論理AND): 左右がともにTRUEの場合にTRUEを返します。 -
|(論理OR): 左右のいずれか、または両方がTRUEの場合にTRUEを返します。
& や | の代わりに
&& や ||
が使われることもありますが、これらはベクトルの最初の要素だけを見て残りを無視します。データ解析では、通常1文字の演算子(&
や
|)を使用し、2文字の演算子はプログラミング(ステートメントの実行を決定する際など)で使用してください。
-
!(論理NOT):TRUEをFALSEに、FALSEをTRUEに変換します。単一の条件(例:!TRUEはFALSEになる)や、ベクトル全体(例:!c(TRUE, FALSE)はc(FALSE, TRUE)になる)を否定できます。
また、単一のベクトル内の要素を比較するために、all(すべての要素が
TRUE の場合に TRUE を返す)や
any(1つ以上の要素が TRUE の場合に
TRUE を返す)関数を使用できます。
チャレンジ 2
以下のコードを用いて:
R
x <- c(5.4, 6.2, 7.1, 4.8, 7.5)
names(x) <- c('a', 'b', 'c', 'd', 'e')
print(x)
出力
a b c d e
5.4 6.2 7.1 4.8 7.5 x から 4 より大きく 7
未満の値を返すサブセットコマンドを書いてください。
R
x_subset <- x[x<7 & x>4]
print(x_subset)
出力
a b d
5.4 6.2 4.8 ヒント: 重複する名前
1つのベクトル内で複数の要素が同じ名前を持つことも可能です(データフレームでは、列名が重複することはありますが、行名は一意である必要があります)。以下の例を考えてみてください:
R
x <- 1:3
x
出力
[1] 1 2 3R
names(x) <- c('a', 'a', 'a')
x
出力
a a a
1 2 3 R
x['a'] # 最初の値のみを返す
出力
a
1 R
x[names(x) == 'a'] # すべての値を返す
出力
a a a
1 2 3 ヒント: 演算子に関するヘルプを得る方法
演算子を引用符で囲むことで、ヘルプを検索できます:help("%in%") または ?"%in%"。
名前付き要素をスキップする
名前付き要素をスキップまたは削除するのは少し難しいです。文字列を否定してスキップしようとすると、R は「文字列を否定する方法が分からない」というやや分かりにくいエラーを出します:
R
x <- c(a=5.4, b=6.2, c=7.1, d=4.8, e=7.5) # もう一度その場でベクトルに名前を付ける
x[-"a"]
エラー
Error in -"a": invalid argument to unary operatorしかし、!=(等しくない)演算子を使用して論理ベクトルを構築すれば、望む動作を実現できます:
R
x[names(x) != "a"]
出力
b c d e
6.2 7.1 4.8 7.5 複数の名前付きインデックスをスキップするのはさらに難しいです。例えば、"a"
と "c" を削除しようとして次のように試みます:
R
x[names(x)!=c("a","c")]
警告
Warning in names(x) != c("a", "c"): longer object length is not a multiple of
shorter object length出力
b c d e
6.2 7.1 4.8 7.5 R は 何か をしましたが、警告を出しており、それが示す通り
間違った結果 を返しました("c"
要素がまだベクトルに含まれています)。
!=
がこの場合に何を実際にしているのかは、非常に良い質問です。
リサイクル
このコードの比較部分を見てみましょう:
R
names(x) != c("a", "c")
警告
Warning in names(x) != c("a", "c"): longer object length is not a multiple of
shorter object length出力
[1] FALSE TRUE TRUE TRUE TRUEnames(x)[3] != "c" は明らかに偽なのに、なぜ R
はこのベクトルの3番目の要素に TRUE
を返すのでしょうか?!= を使用すると、R
は左辺の各要素を右辺の対応する要素と比較しようとします。左辺と右辺の長さが異なる場合はどうなりますか?
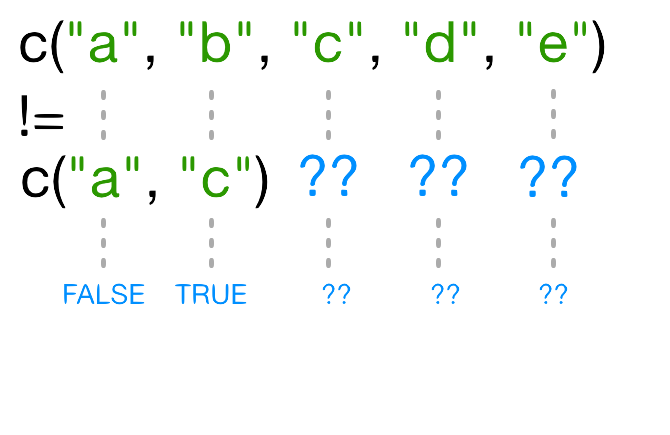
一方のベクトルがもう一方より短い場合、短いベクトルは リサイクル されます:
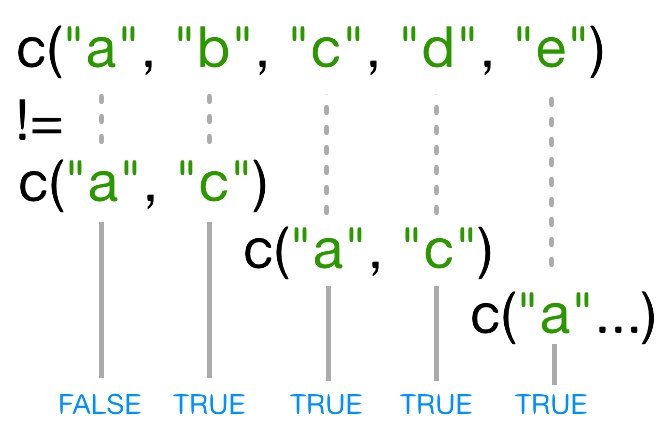
この場合、R は c("a", "c") を必要な回数だけ繰り返して
names(x)
と一致させます(例:c("a","c","a","c","a"))。
再利用された "a" が names(x)
の3番目の要素と一致しないため、!= の結果が
TRUE になります。
リサイクルによりこのような間違いが発生するのを防ぐには
%in%
演算子を使用します。この演算子は左辺の各要素について、右辺の中にその要素が存在するかどうかを確認します。今回は値を除外したいので、!
演算子も使用します:
R
x[! names(x) %in% c("a","c") ]
出力
b d e
6.2 4.8 7.5 チャレンジ 3
ベクトルの要素を、特定のリスト内のいずれかと一致させる操作は、データ解析で非常に一般的なタスクです。例えば、gapminder
データセットには country と continent
の変数がありますが、これらの間の情報は含まれていません。東南アジアの情報を抽出したいとします。このとき、どのようにして東南アジアのすべての国について
TRUE、それ以外を FALSE
とする論理ベクトルを作成しますか?
以下のデータを使用します:
R
seAsia <- c("Myanmar","Thailand","Cambodia","Vietnam","Laos")
## エピソード2でダウンロードした gapminder データを読み込む
gapminder <- read.csv("data/gapminder_data.csv", header=TRUE)
## データフレームから `country` 列を抽出(詳細は後述);
## factor を文字列に変換;
## 重複しない要素のみ取得
countries <- unique(as.character(gapminder$country))
以下の3つの方法を試し、それぞれがどのように(正しくない、または正しい方法で)動作するのか説明してください:
-
間違った方法(
==のみを使用) -
不格好な方法(論理演算子
==と|を使用) -
エレガントな方法(
%in%を使用)
間違った方法
countries==seAsia
この方法では、警告("In countries == seAsia : 長いオブジェクトの長さが短いオブジェクトの長さの倍数ではありません")が表示され、誤った結果(すべてFALSEのベクトル)が返されます。これは、seAsiaの再利用された値が正しい位置に一致しないためです。不格好な方法
以下のコードでは正しい値を得ることができますが、非常に冗長で扱いにくいです:
R
(countries=="Myanmar" | countries=="Thailand" |
countries=="Cambodia" | countries == "Vietnam" | countries=="Laos")
または、countries==seAsia[1] | countries==seAsia[2] | ...
のように記述します。
リストが長い場合、さらに複雑になります。
-
エレガントな方法
countries %in% seAsia
この方法は正確で、記述が簡単で可読性も高いです。
特殊値の扱い
R
では、欠損値、無限値、未定義値を処理できない関数に出会うことがあります。
そのようなデータをフィルタリングするために、以下の特殊な関数を使用できます:
-
is.na:ベクトル、行列、またはデータフレーム内のNA(またはNaN)を含む位置を返します。 - 同様に、
is.nanとis.infiniteは、それぞれNaNとInfに対応します。 -
is.finite:NA、NaN、Infを含まない位置を返します。 -
na.omit:ベクトルからすべての欠損値を除外します。
因子のサブセット
ベクトルのサブセット方法を学んだところで、他のデータ構造のサブセットについて考えてみましょう。
因子のサブセットは、ベクトルのサブセットと同じ方法で行えます。
R
f <- factor(c("a", "a", "b", "c", "c", "d"))
f[f == "a"]
出力
[1] a a
Levels: a b c dR
f[f %in% c("b", "c")]
出力
[1] b c c
Levels: a b c dR
f[1:3]
出力
[1] a a b
Levels: a b c d要素をスキップしても、そのカテゴリが因子レベルから削除されるわけではありません:
R
f[-3]
出力
[1] a a c c d
Levels: a b c d行列のサブセット
行列は [
関数を使用してサブセットします。この場合、2つの引数を取り、1つ目は行、2つ目は列に適用されます:
R
set.seed(1)
m <- matrix(rnorm(6*4), ncol=4, nrow=6)
m[3:4, c(3,1)]
出力
[,1] [,2]
[1,] 1.12493092 -0.8356286
[2,] -0.04493361 1.5952808行または列全体を取得する場合は、1つ目または2つ目の引数を空白のままにします:
R
m[, c(3,4)]
出力
[,1] [,2]
[1,] -0.62124058 0.82122120
[2,] -2.21469989 0.59390132
[3,] 1.12493092 0.91897737
[4,] -0.04493361 0.78213630
[5,] -0.01619026 0.07456498
[6,] 0.94383621 -1.989351701つの行または列のみを取得すると、結果が自動的にベクトルに変換されます:
R
m[3,]
出力
[1] -0.8356286 0.5757814 1.1249309 0.9189774結果を行列として保持するには、第3引数 を指定して
drop = FALSE を設定します:
R
m[3, , drop=FALSE]
出力
[,1] [,2] [,3] [,4]
[1,] -0.8356286 0.5757814 1.124931 0.9189774行または列の外側をアクセスしようとすると、R はエラーをスローします:
R
m[, c(3,6)]
エラー
Error in m[, c(3, 6)]: subscript out of boundsヒント: 高次元配列
多次元配列の場合、[
の各引数が次元に対応します。例えば、3次元配列の場合、最初の3つの引数が行、列、および深さ次元に対応します。
行列はベクトルであるため、1つの引数だけを使用してサブセットを取ることもできます:
R
m[5]
出力
[1] 0.3295078これは通常あまり有用ではなく、読み取りづらい場合があります。ただし、行列がデフォルトで 列優先フォーマット に配置されていることを理解するのに役立ちます。つまり、ベクトルの要素は列ごとに配置されます:
R
matrix(1:6, nrow=2, ncol=3)
出力
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6行ごとに行列を埋めたい場合は、byrow=TRUE
を使用します:
R
matrix(1:6, nrow=2, ncol=3, byrow=TRUE)
出力
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6行列は、行および列のインデックスの代わりに、その行名および列名を使用してサブセットを取ることもできます。
チャレンジ 4
以下のコードを用いて:
R
m <- matrix(1:18, nrow=3, ncol=6)
print(m)
出力
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 4 7 10 13 16
[2,] 2 5 8 11 14 17
[3,] 3 6 9 12 15 18- 以下のコマンドのうち、11 と 14 を抽出するものはどれでしょうか?
A. m[2,4,2,5]
B. m[2:5]
C. m[4:5,2]
D. m[2,c(4,5)]
D
リストのサブセット
ここでは新しいサブセット演算子を紹介します。リストをサブセットするためには、3つの関数を使用します。これらは、原子ベクトルや行列を学ぶ際にも登場しました:[,
[[, $ です。
[
を使用すると、常にリストが返されます。リストから要素を「抽出」するのではなく「サブセット」したい場合に使用します。
R
xlist <- list(a = "Software Carpentry", b = 1:10, data = head(mtcars))
xlist[1]
出力
$a
[1] "Software Carpentry"このコードは、1つの要素を含むリスト を返します。
リストの要素は、原子ベクトルと同じ方法でサブセットできます。ただし、比較演算は再帰的ではなく、リスト内のデータ構造に基づいて条件が評価されるため、リスト内の個々の要素には適用されません。
R
xlist[1:2]
出力
$a
[1] "Software Carpentry"
$b
[1] 1 2 3 4 5 6 7 8 9 10リストの個々の要素を抽出するには、二重角括弧関数 [[
を使用する必要があります。
R
xlist[[1]]
出力
[1] "Software Carpentry"この結果はリストではなくベクトルであることに注意してください。
複数の要素を一度に抽出することはできません:
R
xlist[[1:2]]
エラー
Error in xlist[[1:2]]: subscript out of boundsまた、要素をスキップすることもできません:
R
xlist[[-1]]
エラー
Error in xlist[[-1]]: invalid negative subscript in get1index <real>ただし、名前を使用して要素をサブセットおよび抽出することは可能です:
R
xlist[["a"]]
出力
[1] "Software Carpentry"$
演算子は、名前で要素を抽出するための簡潔な記法を提供します:
R
xlist$data
出力
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1チャレンジ 5
以下のリストが与えられています:
R
xlist <- list(a = "Software Carpentry", b = 1:10, data = head(mtcars))
リストとベクトルのサブセット方法を用いて、xlist
から数字の 2 を抽出してください。
ヒント:数字の 2 はリスト内の "b" に含まれています。
R
xlist$b[2]
出力
[1] 2R
xlist[[2]][2]
出力
[1] 2R
xlist[["b"]][2]
出力
[1] 2チャレンジ 6
以下の線形モデルが与えられています:
R
mod <- aov(pop ~ lifeExp, data=gapminder)
残差の自由度を抽出してください(ヒント:attributes()
が役立ちます)。
R
attributes(mod) ## `df.residual` は `mod` の名前の1つです
R
mod$df.residual
データフレーム
データフレームは内部的にはリストであることを覚えておきましょう。そのため、同様のルールが適用されます。ただし、データフレームは2次元のオブジェクトでもあります:
[
に1つの引数を与える場合、リストと同様に動作し、それぞれのリスト要素が列に対応します。結果として得られるオブジェクトはデータフレームになります:
R
head(gapminder[3])
出力
pop
1 8425333
2 9240934
3 10267083
4 11537966
5 13079460
6 14880372同様に、[[ を使用すると、単一の列
を抽出します:
R
head(gapminder[["lifeExp"]])
出力
[1] 28.801 30.332 31.997 34.020 36.088 38.438$
演算子は、列を名前で抽出するための便利なショートカットを提供します:
R
head(gapminder$year)
出力
[1] 1952 1957 1962 1967 1972 19772つの引数を与えると、[
は行列と同じように動作します:
R
gapminder[1:3,]
出力
country year pop continent lifeExp gdpPercap
1 Afghanistan 1952 8425333 Asia 28.801 779.4453
2 Afghanistan 1957 9240934 Asia 30.332 820.8530
3 Afghanistan 1962 10267083 Asia 31.997 853.1007単一行をサブセットすると、結果はデータフレームになります(要素が混合型のためです):
R
gapminder[3,]
出力
country year pop continent lifeExp gdpPercap
3 Afghanistan 1962 10267083 Asia 31.997 853.1007ただし、単一列をサブセットすると結果はベクトルになります(第3引数
drop = FALSE を指定することで変更可能)。
チャレンジ 7
以下の一般的なデータフレームサブセットエラーを修正してください:
- 年 1957 の観測値を抽出する
- 1列目から4列目以外のすべての列を抽出する
R
gapminder[,-1:4]
- 寿命が80年以上の行を抽出する
R
gapminder[gapminder$lifeExp > 80]
- 1行目と4列目、5列目(
continentとlifeExp)を抽出する
R
gapminder[1, 4, 5]
- 応用:年 2002 年と 2007 年の情報を含む行を抽出する
R
gapminder[gapminder$year == 2002 | 2007,]
以下の一般的なデータフレームサブセットエラーを修正:
- 年 1957 の観測値を抽出する
R
# gapminder[gapminder$year = 1957,]
gapminder[gapminder$year == 1957,]
- 1列目から4列目以外のすべての列を抽出する
R
# gapminder[,-1:4]
gapminder[,-c(1:4)]
- 寿命が80年以上の行を抽出する
R
# gapminder[gapminder$lifeExp > 80]
gapminder[gapminder$lifeExp > 80,]
- 1行目と4列目、5列目(
continentとlifeExp)を抽出する
R
# gapminder[1, 4, 5]
gapminder[1, c(4, 5)]
- 応用:年 2002 年と 2007 年の情報を含む行を抽出する
R
# gapminder[gapminder$year == 2002 | 2007,]
gapminder[gapminder$year == 2002 | gapminder$year == 2007,]
gapminder[gapminder$year %in% c(2002, 2007),]
チャレンジ 8
なぜ
gapminder[1:20]はエラーを返すのでしょうか?gapminder[1:20, ]とはどう異なるのでしょうか?行 1 から 9 と 19 から 23 のみを含む新しい
data.frameを作成し、それをgapminder_smallと名付けてください。この操作は 1 ステップまたは 2 ステップで行うことができます。
gapminderは data.frame なので、2 次元でサブセット化する必要があります。gapminder[1:20, ]は最初の 20 行とすべての列をサブセット化して返します。
R
gapminder_small <- gapminder[c(1:9, 19:23),]
まとめ
- R のインデックスは 0 ではなく 1 から始まります。
-
[]を使用して位置による個々の値にアクセスします。 -
[low:high]を使用してデータのスライスにアクセスします。 -
[c(...)]を使用して任意のデータセットにアクセスします。 - 論理演算や論理ベクトルを使用してデータのサブセットにアクセスします。