Subsetting Data
最終更新日:2025-11-11 | ページの編集
所要時間: 50分
概要
質問
- How can I work with subsets of data in R?
目的
- To be able to subset vectors, factors, matrices, lists, and data frames
- To be able to extract individual and multiple elements: by index, by name, using comparison operations
- To be able to skip and remove elements from various data structures.
R has many powerful subset operators. Mastering them will allow you to easily perform complex operations on any kind of dataset.
オブジェクトを部分集合する方法は6つあり、データ構造を 部分集合する方法は3つあります。
Rの働き頭、数値ベクトルから始めましょう。
R
x <- c(5.4, 6.2, 7.1, 4.8, 7.5)
names(x) <- c('a', 'b', 'c', 'd', 'e')
x
出力
a b c d e
5.4 6.2 7.1 4.8 7.5 原子ベクトル
Rでは、文字列、数値、論理値を含む単純なベクトルは、 原子(atomic) ベクトルと呼ばれています。その理由は、原子ベクトルはそれ以上単純化できないからです。
練習用のベクトルを作ることができたのですが、どうやってベクトルの中身を使うのでしょう?
要素番号で要素を使う
ベクトルの要素を抽出するためには、対応する1から始まる要素番号を使います:
R
x[1]
出力
a
5.4 R
x[4]
出力
d
4.8 It may look different, but the square brackets operator is a function. For vectors (and matrices), it means “get me the nth element”.
複数の要素を一度に頼むこともできます:
R
x[c(1, 3)]
出力
a c
5.4 7.1 または、ベクトルのスライスを頼むこともできます:
R
x[1:4]
出力
a b c d
5.4 6.2 7.1 4.8 この :
演算子は、左から右の要素の一連番号を作ります。
R
1:4
出力
[1] 1 2 3 4R
c(1, 2, 3, 4)
出力
[1] 1 2 3 4同じ要素を何度も頼むこともできます:
R
x[c(1,1,3)]
出力
a a c
5.4 5.4 7.1 もしベクトルの長さ以上の要素番号を頼んだ場合、Rは欠測値を返します:
R
x[6]
出力
<NA>
NA これは、 NA を含む、NA
という名前の長さ1のベクトルです。
もし、0番目の要素を頼んだ場合、空ベクトルが返ってきます:
R
x[0]
出力
named numeric(0)Rのベクトル番号は、1から始まる
多くのプログラミング言語(例えば、C、Python)では、ベクトルの最初の 要素の要素番号は0です。Rでは、最初の要素番号は1です。 In R, the first element is 1.
要素を飛ばす、削除する
もし、負の番号をベクトルの要素番号として使った場合、Rは指定された番号 以外の 全ての要素を返します:
R
x[-2]
出力
a c d e
5.4 7.1 4.8 7.5 複数の要素を飛ばすこともできます:
R
x[c(-1, -5)] # or x[-c(1,5)]
出力
b c d
6.2 7.1 4.8 ヒント:演算の順番
初心者によく見られるのが、ベクトルのスライスを飛ばそうとする時に起こる間違いです。 It’s natural to try to negate a sequence like so:
R
x[-1:3]
This gives a somewhat cryptic error:
エラー
Error in x[-1:3]: only 0's may be mixed with negative subscripts演算の順番を思い出してみましょう。:
は、実際には関数なのです。
最初の引数を-1、次の引数を3として認識し、次のような数列を生成します。
c(-1, 0, 1, 2, 3)
正解は、関数を呼ぶ部分を括弧で囲むことです。
そうすると関数の結果全てに- の演算子が適応されます: ~~~
x[-(:)] ~~~ ~~~ d e:
R
x[-(1:3)]
出力
d e
4.8 7.5 ベクトルから要素を削除するには、結果を変数に戻してやる必要があります。
R
x <- x[-4]
x
出力
a b c e
5.4 6.2 7.1 7.5 チャレンジ1
以下のリストがあるとします:
R
x <- c(5.4, 6.2, 7.1, 4.8, 7.5)
names(x) <- c('a', 'b', 'c', 'd', 'e')
print(x)
出力
a b c d e
5.4 6.2 7.1 4.8 7.5 以下の出力を得るために、少なくとも2つの異なるコマンドを考えてください: ~~~ b c d:
出力
b c d
6.2 7.1 4.8 After you find 2 different commands, compare notes with your neighbour. Did you have different strategies?
R
x[2:4]
出力
b c d
6.2 7.1 4.8 R
x[-c(1,5)]
出力
b c d
6.2 7.1 4.8 R
x[c(2,3,4)]
出力
b c d
6.2 7.1 4.8 名前で部分集合を作る
要素番号で抜き出す代わりに、名前で要素を抽出することもできます。
R
x <- c(a=5.4, b=6.2, c=7.1, d=4.8, e=7.5) # ベクトルを'その場で'名づけることができます x[c("a", "c")]
オブジェクトの部分集合を作るには、この方法の方が確実です:要素の場所は、 部分集合の演算子を繋いで使うことでよく変わるのですが、 名前は絶対に変わりません。
Subsetting through other logical operations
どんな論理ベクトルでも部分集合を作ることができます:
R
x[c(FALSE, FALSE, TRUE, FALSE, TRUE)]
出力
c e
7.1 7.5 つまり、以下の宣言は、前と同じ結果を返します。
R
x[x > 7]
出力
c e
7.1 7.5 分割すると、この宣言は最初に x 7 を計算し、論理ベクトル
c(FALSE, FALSE, TRUE, FALSE, TRUE) を作ります。それから、
TRUE の値に対応する要素を x
から選択しています。
名前で特定するという既出の方法を真似するため、 ==
を使うこともできます。 (比較には、 = ではなく、
== を使わないといけません):
R
x[names(x) == "a"]
出力
a
5.4 ヒント:論理条件を組み合わせる
We often want to combine multiple logical criteria. For example, we might want to find all the countries that are located in Asia or Europe and have life expectancies within a certain range. Several operations for combining logical vectors exist in R:
-
&, the “logical AND” operator: returnsTRUEif both the left and right areTRUE. -
|, the “logical OR” operator: returnsTRUE, if either the left or right (or both) areTRUE.
You may sometimes see && and ||
instead of & and |. These two-character
operators only look at the first element of each vector and ignore the
remaining elements. In general you should not use the two-character
operators in data analysis; save them for programming, i.e. deciding
whether to execute a statement.
-
!, the “logical NOT” operator: convertsTRUEtoFALSEandFALSEtoTRUE. It can negate a single logical condition (eg!TRUEbecomesFALSE), or a whole vector of conditions(eg!c(TRUE, FALSE)becomesc(FALSE, TRUE)).
Additionally, you can compare the elements within a single vector
using the all function (which returns TRUE if
every element of the vector is TRUE) and the
any function (which returns TRUE if one or
more elements of the vector are TRUE).
チャレンジ2
以下のリストがあるとします:
R
x <- c(5.4, 6.2, 7.1, 4.8, 7.5)
names(x) <- c('a', 'b', 'c', 'd', 'e')
print(x)
出力
a b c d e
5.4 6.2 7.1 4.8 7.5 4よりも大きく7より小さいxの値を返す部分集合を作るコマンドを書きましょう。
R
x_subset <- x[x<7 & x>4]
print(x_subset)
出力
a b d
5.4 6.2 4.8 ヒント:同じ名前がある場合
You should be aware that it is possible for multiple elements in a vector to have the same name. (For a data frame, columns can have the same name — although R tries to avoid this — but row names must be unique.) Consider these examples:
R
x <- 1:3
x
出力
[1] 1 2 3R
names(x) <- c('a', 'a', 'a')
x
出力
a a a
1 2 3 R
x['a'] # only returns first value
出力
a
1 R
x[names(x) == 'a'] # returns all three values
出力
a a a
1 2 3 ヒント:演算子についてのヘルプを見る
演算子を引用符で囲むことで、演算子についてのヘルプを検索できることを覚えておきましょう:
help("%in%") または ?"%in%".
名前のある要素を飛ばす
Skipping or removing named elements is a little harder. 名前のある要素を飛ばしたり削除したりすることは少しだけ難しくなります。もし、ある文字列にマイナス記号を付けて飛ばそうとすると、Rは文字列にマイナス記号を付ける方法を知らないと(若干控えめに)抗議するでしょう:
R
x <- c(a=5.4, b=6.2, c=7.1, d=4.8, e=7.5) # まず、ベクトルにその場で名前を付けることから始めます x[-"a"]
でも、!=
(不等号)演算子を使えば、やってもらいたかったことをしてくれる論理ベクトルが作れます:
R
x[names(x) != "a"]
出力
b c d e
6.2 7.1 4.8 7.5 Skipping multiple named indices is a little bit harder still. Suppose
we want to drop the "a" and "c" elements, so
we try this:
R
x[names(x)!=c("a","c")]
警告
Warning in names(x) != c("a", "c"): longer object length is not a multiple of
shorter object length出力
b c d e
6.2 7.1 4.8 7.5 Rは 何か
をしたのですが、私達が注目しなければならない警告も出しました。結果としては、どうやら
間違った回答 が帰ってきたみたいです("c"
の要素が、ベクトルに含まれています)!
So what does != actually do in this case? That’s an
excellent question.
再利用
このコードの比較する部分を見てみましょう:
R
names(x) != c("a", "c")
警告
Warning in names(x) != c("a", "c"): longer object length is not a multiple of
shorter object length出力
[1] FALSE TRUE TRUE TRUE TRUERは、names(x)[3] != "c"
が明らかに間違いであるときに、このベクトルの3番目の要素をなぜTRUE
にしたのでしょうか。 !=
を使うとき、Rは左側の引数のそれぞれの要素を右側のそれぞれの要素と比較しようとします。
違う長さのベクトルを比較しようとすると、何が起こるのでしょう?
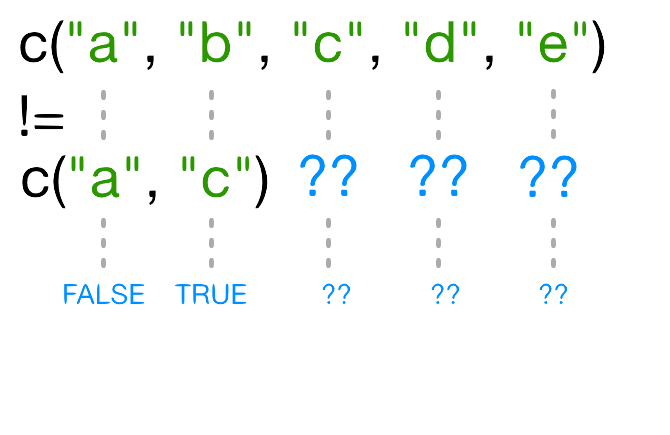
もし、もう一つのベクトルよりも短いベクトルがあったとき、そのベクトルは 再利用されます :
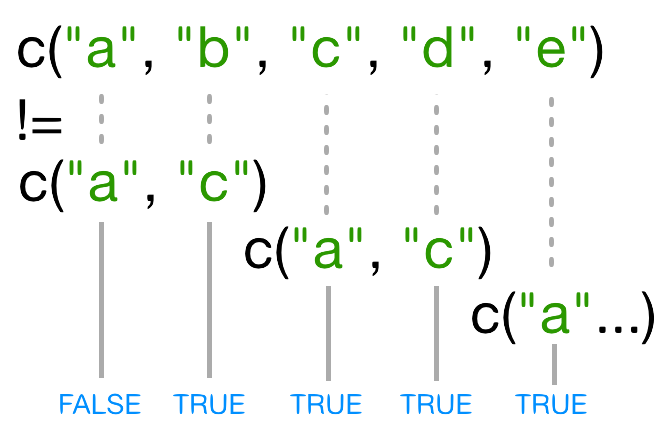
In this case R repeats c("a", "c") as
many times as necessary to match names(x), i.e. we get
c("a","c","a","c","a"). Since the recycled "a"
doesn’t match the third element of names(x), the value of
!= is TRUE. Because in this case the longer
vector length (5) isn’t a multiple of the shorter vector length (2), R
printed a warning message. If we had been unlucky and
names(x) had contained six elements, R would
silently have done the wrong thing (i.e., not what we intended
it to do). This recycling rule can can introduce hard-to-find and subtle
bugs!
The way to get R to do what we really want (match each
element of the left argument with all of the elements of the
right argument) it to use the %in% operator. The
%in% operator goes through each element of its left
argument, in this case the names of x, and asks, “Does this
element occur in the second argument?”. Here, since we want to
exclude values, we also need a ! operator to
change “in” to “not in”:
R
x[! names(x) %in% c("a","c") ]
出力
b d e
6.2 4.8 7.5 チャレンジ3
Selecting elements of a vector that match any of a list of components
is a very common data analysis task. For example, the gapminder data set
contains country and continent variables, but
no information between these two scales. Suppose we want to pull out
information from southeast Asia: how do we set up an operation to
produce a logical vector that is TRUE for all of the
countries in southeast Asia and FALSE otherwise?
Suppose you have these data:
R
seAsia <- c("Myanmar","Thailand","Cambodia","Vietnam","Laos")
## read in the gapminder data that we downloaded in episode 2
gapminder <- read.csv("data/gapminder_data.csv", header=TRUE)
## extract the `country` column from a data frame (we'll see this later);
## convert from a factor to a character;
## and get just the non-repeated elements
countries <- unique(as.character(gapminder$country))
There’s a wrong way (using only ==), which will give you
a warning; a clunky way (using the logical operators == and
|); and an elegant way (using %in%). See
whether you can come up with all three and explain how they (don’t)
work.
- The wrong way to do this problem is
countries==seAsia. This gives a warning ("In countries == seAsia : longer object length is not a multiple of shorter object length") and the wrong answer (a vector of allFALSEvalues), because none of the recycled values ofseAsiahappen to line up correctly with matching values incountry. - The clunky (but technically correct) way to do this problem is
R
(countries=="Myanmar" | countries=="Thailand" |
countries=="Cambodia" | countries == "Vietnam" | countries=="Laos")
(or countries==seAsia[1] | countries==seAsia[2] | ...).
This gives the correct values, but hopefully you can see how awkward it
is (what if we wanted to select countries from a much longer list?).
- The best way to do this problem is
countries %in% seAsia, which is both correct and easy to type (and read).
特別な値を扱う
ある時点で、欠測値、無限値、未定義のデータを扱えないRの関数に出会うことでしょう。
データをフィルターするために使える特別な関数がいくつかあります:
-
is.naは、ベクトル、行列、データフレームで、 - likewise,
is.nan, andis.infinitewill do the same forNaNandInf. -
is.finitewill return all positions in a vector, matrix, or data.frame that do not containNA,NaNorInf. -
na.omitwill filter out all missing values from a vector
順序のない因子の部分集合を作る
これまで部分集合ベクトルを作る色々な方法をやってみましたが、 他のデータ構造の部分集合を作るにはどうすればいいでしょう。
順序なし因子の部分集合を作る方法は、ベクトルの部分集合を作る方法と同じです。
R
f <- factor(c("a", "a", "b", "c", "c", "d"))
f[f == "a"]
出力
[1] a a
Levels: a b c dR
f[f %in% c("b", "c")]
出力
[1] b c c
Levels: a b c dR
f[1:3]
出力
[1] a a b
Levels: a b c d要素を飛ばし、その順序なし因子に該当カテゴリーが存在しない場合であっても、水準は削除されません:
R
f[-3]
出力
[1] a a c c d
Levels: a b c d行列の部分周到を作る
Matrices are also subsetted using the [ function. In
this case it takes two arguments: the first applying to the rows, the
second to its columns:
R
set.seed(1)
m <- matrix(rnorm(6*4), ncol=4, nrow=6)
m[3:4, c(3,1)]
出力
[,1] [,2]
[1,] 1.12493092 -0.8356286
[2,] -0.04493361 1.5952808それぞれ全ての列または行を取ってくるためには、最初または2番目の引数を空のままにしておきましょう:
R
m[, c(3,4)]
出力
[,1] [,2]
[1,] -0.62124058 0.82122120
[2,] -2.21469989 0.59390132
[3,] 1.12493092 0.91897737
[4,] -0.04493361 0.78213630
[5,] -0.01619026 0.07456498
[6,] 0.94383621 -1.989351701つの列または行にアクセスした場合、Rは結果を自動的にベクトルに変換します:
R
m[3,]
出力
[1] -0.8356286 0.5757814 1.1249309 0.9189774もし、アウトプットを行列のままにしておきたいなら、 3番目の 因数、
drop = FALSE が必要です:
R
m[3, , drop=FALSE]
出力
[,1] [,2] [,3] [,4]
[1,] -0.8356286 0.5757814 1.124931 0.9189774ベクトルと違って、行列の外の行や列にアクセスしようとすると、Rはエラーを返します:
R
m[, c(3,6)]
エラー
Error in m[, c(3, 6)]: subscript out of boundsヒント:高次元列
多次元列を扱う際、[
のそれぞれの引数は、次元に対応しています。
例えば、3次元列は、最初の3つの引数が、行、列、次元の深さに対応してます。
行列はベクトルなので、1つの引数だけを使って部分集合を作ることもできます:
R
m[5]
出力
[1] 0.3295078This usually isn’t useful, and often confusing to read. However it is useful to note that matrices are laid out in column-major format by default. That is the elements of the vector are arranged column-wise:
R
matrix(1:6, nrow=2, ncol=3)
出力
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6もし、行列を行の順番で埋めていきたい場合は、 byrow=TRUE
を使います:
R
matrix(1:6, nrow=2, ncol=3, byrow=TRUE)
出力
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6行列もまた、行及び列の要素番号の代わりに、名前で部分集合を作ることができます。
チャレンジ4
以下のリストがあるとします:
R
m <- matrix(1:18, nrow=3, ncol=6)
print(m)
出力
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 4 7 10 13 16
[2,] 2 5 8 11 14 17
[3,] 3 6 9 12 15 18- 次のコマンドのうち、11と14を抜き出すことができるコマンドはどれでしょう?
A. m[2,4,2,5]
B. m[2:5]
C. m[4:5,2]
D. m[2,c(4,5)]
D
リストの分部集合を作る
Now we’ll introduce some new subsetting operators. There are three
functions used to subset lists. We’ve already seen these when learning
about atomic vectors and matrices: [, [[, and
$.
Using [ will always return a list. If you want to
subset a list, but not extract an element, then you
will likely use [.
R
xlist <- list(a = "Software Carpentry", b = 1:10, data = head(mtcars))
xlist[1]
出力
$a
[1] "Software Carpentry"これは、 1つの要素を持つリスト です。
[
を使って原子ベクトルを作ったのと全く同じ方法で、リストの要素から部分集合を作ることができます。
しかし、比較処理は反復的ではないため、使えません。比較処理は、リストのそれぞれの要素のデータ構造にある、個々の要素ではなく、
データ構造に条件付けをしようとするからです。
R
xlist[1:2]
出力
$a
[1] "Software Carpentry"
$b
[1] 1 2 3 4 5 6 7 8 9 10リストの個々の要素を抜き出すためには、二重角括弧 [[
を使う必要があります:
R
xlist[[1]]
出力
[1] "Software Carpentry"ここで結果がリストではなく、ベクトルとなっていることに気をつけましょう。
1つの要素を同時に抜き出すことはできません:
R
xlist[[1:2]]
エラー
Error in xlist[[1:2]]: subscript out of boundsまた、要素を飛ばすこともできません:
R
xlist[[-1]]
エラー
Error in xlist[[-1]]: invalid negative subscript in get1index <real>でも両方の部分集合の名前を使って、要素を抽出することはできます:
R
xlist[["a"]]
出力
[1] "Software Carpentry"$ 関数は、簡単に名前で要素を抽出できるものです。
R
xlist$data
出力
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1チャレンジ5
以下のリストがあるとします:
R
xlist <- list(a = "Software Carpentry", b = 1:10, data = head(mtcars))
Using your knowledge of both list and vector subsetting, extract the number 2 from xlist. ヒント:数字の2は、リスト「b」の中にあります。
R
xlist$b[2]
出力
[1] 2R
xlist[[2]][2]
出力
[1] 2R
xlist[["b"]][2]
出力
[1] 2チャレンジ6
以下のような線形モデルあるとします:
R
mod <- aov(pop ~ lifeExp, data=gapminder)
Extract the residual degrees of freedom (hint:
attributes() will help you)
R
attributes(mod) ## `df.residual` is one of the names of `mod`
R
mod$df.residual
データフレーム
データフレームの中身は実はリストなので、リストと同じようなルールがあてはまることを覚えておきましょう。 しかし、データフレームは2次元のオブジェクトでもあります。
1つの引数しかない [
は、リストと同じような働きがあり、それぞれのリストの要素が列に対応します。
その結果、返されるオブジェクトはデータフレームになります:
R
head(gapminder[3])
出力
pop
1 8425333
2 9240934
3 10267083
4 11537966
5 13079460
6 14880372同様に、 [[ は、 単一の列
を抜き出す働きをするものです:
R
head(gapminder[["lifeExp"]])
出力
[1] 28.801 30.332 31.997 34.020 36.088 38.438そして $ は、簡単に列名で列を抽出できるものです:
R
head(gapminder$year)
出力
[1] 1952 1957 1962 1967 1972 19772つの引数を使えば、 [
は、行列と同じような働きをします:
R
gapminder[1:3,]
出力
country year pop continent lifeExp gdpPercap
1 Afghanistan 1952 8425333 Asia 28.801 779.4453
2 Afghanistan 1957 9240934 Asia 30.332 820.8530
3 Afghanistan 1962 10267083 Asia 31.997 853.1007もし、1つの行を部分集合する場合、結果はデータフレームになります (理由は、要素には色々なデータ型が混ざっているからです):
R
gapminder[3,]
出力
country year pop continent lifeExp gdpPercap
3 Afghanistan 1962 10267083 Asia 31.997 853.1007しかし、1つの行についての結果は、ベクトルになります
(これは、3番目の引数を drop = FALSE
とすれば変えられます)。
チャレンジ7
Fix each of the following common data frame subsetting errors:
- Extract observations collected for the year 1957
- Extract all columns except 1 through to 4
R
gapminder[,-1:4]
- Extract the rows where the life expectancy is longer the 80 years
R
gapminder[gapminder$lifeExp > 80]
- Extract the first row, and the fourth and fifth columns
(
continentandlifeExp).
R
gapminder[1, 4, 5]
- Advanced: extract rows that contain information for the years 2002 and 2007
R
gapminder[gapminder$year == 2002 | 2007,]
Fix each of the following common data frame subsetting errors:
- Extract observations collected for the year 1957
R
# gapminder[gapminder$year = 1957,]
gapminder[gapminder$year == 1957,]
- Extract all columns except 1 through to 4
R
# gapminder[,-1:4]
gapminder[,-c(1:4)]
- Extract the rows where the life expectancy is longer than 80 years
R
# gapminder[gapminder$lifeExp > 80]
gapminder[gapminder$lifeExp > 80,]
- Extract the first row, and the fourth and fifth columns
(
continentandlifeExp).
R
# gapminder[1, 4, 5]
gapminder[1, c(4, 5)]
- Advanced: extract rows that contain information for the years 2002 and 2007
R
# gapminder[gapminder$year == 2002 | 2007,]
gapminder[gapminder$year == 2002 | gapminder$year == 2007,]
gapminder[gapminder$year %in% c(2002, 2007),]
チャレンジ8
なぜ、
gapminder[1:20]は、エラーを返すのでしょうか?gapminder[1:20, ]とどう違うのでしょう?新しく
gapminder_smallという、1から9の行だけを含むdata.frameを作ってください。 これは、1つまたは2つの手順でできます。
gapminderは、データフレームなので、2つの次元の部分集合を作る必要があります。gapminder[1:20, ]は、最初から20番目の行までについて全ての列を引き出します。
R
gapminder_small <- gapminder[c(1:9, 19:23),]
- Indexing in R starts at 1, not 0.
- Access individual values by location using
[]. - Access slices of data using
[low:high]. - Access arbitrary sets of data using
[c(...)]. - Use logical operations and logical vectors to access subsets of data.