RとRStudio
最終更新日:2024-09-08 | ページの編集
概要
質問
- RとRStudioとは何ですか?
目的
- RStudio スクリプト、コンソール、環境、およびプロットペインの目的について説明します。
- Rプロジェクトとして一連の分析のためのファイルとディレクトリを整理し、作業ディレクトリの目的を理解する。
- RStudio 組み込みのヘルプインターフェイスを使用して、R 関数の詳細情報を検索します。
- Rのユーザーコミュニティとトラブルシューティングのために十分な情報を提供する方法を示す。
このエピソードは、Data Carpentriesの_Data Analysis and Visualisation in R for Ecologists_レッスンに基づいています。
Rとは? RStudioとは何ですか?
R](https://www.r-project.org/)という用語は、 プログラミング言語、統計計算_のための_環境 、それを使って書かれたスクリプトを解釈する_ソフトウェア_を指すのに使われる。
RStudioは現在、Rスクリプトを書くだけでなく、R ソフトウェア1と対話するための非常に人気のある方法です。 RStudio を正しく機能させるには、R と が必要です。
RStudio IDE Cheat Sheet](https://raw.githubusercontent.com/rstudio/cheatsheets/main/rstudio-ide.pdf) 、ここで説明するよりもはるかに多くの情報を提供していますが、キーボードショートカットを学んだり、新しい機能を発見したりするのに便利です。
なぜRを学ぶのか?
Rはポインティングやクリックを多用しない。
学習曲線は他のソフトウェアよりも急かもしれないが、 Rを使えば、分析結果は のポインティングとクリックの連続を覚えることに依存するのではなく、代わりに の一連のコマンドを書くことに依存する! そのため、より多くのデータを収集したため、 分析をやり直したい場合、 結果を得るためにどのボタンをどの順番でクリックしたかを覚えておく必要はない。スクリプトを再度実行するだけでよい。
スクリプトを使用することで、分析で使用したステップが明確になり、 、書いたコードを他の誰かが検査することができ、 フィードバックを与え、間違いを発見することができる。
スクリプトを使って仕事をすることで、自分がやっている の内容をより深く理解することになり、自分が使っている メソッドの学習と理解が容易になる。
Rコードは再現性に優れている
再現性とは、同じデータセットから同じ解析コード( )を使ったときに、他の誰か(未来の自分を含む)が 、同じ結果を得られることを意味する。
Rは他のツールと統合し、 のコードから原稿やレポートを作成することができる。 さらにデータを集めたり、データセットの誤りを修正したりすると、原稿や報告書の 図や統計検定が自動的に更新されます。 。
ジャーナルや研究助成機関では、 、再現性のある分析を求めるところが増えている。Rを知っていれば、このような 。
Rは学際的で拡張性がある
機能を拡張するためにインストールできる10000以上のパッケージ2により、Rは、 多くの科学分野からの統計的アプローチを組み合わせることができるフレームワークを提供し、 データの分析に必要な分析フレームワークに最適です。 例えば、 Rには画像分析、GIS、時系列、集団 遺伝学、その他多くのパッケージがある。
, the Comprehensive R Archive Network. From the R Journal, Volume 10/2, December 2018.](fig/cran.png)
Rはあらゆる形や大きさのデータを扱う
Rで学ぶスキルは、 データセットの大きさに合わせて簡単にスケールアップできる。 データセットの行数が数百行であろうと数百万行であろうと、 、大差はないだろう。
Rはデータ分析用に設計されている。 欠損データや統計的 因子の取り扱いを便利にする特別なデータ構造 とデータ型が付属している。
Rは、スプレッドシート、データベース、その他多くのデータ形式、 、コンピュータ上またはウェブ上に接続することができます。
Rは大きく歓迎されるコミュニティ
何千人もの人々が毎日Rを利用している。 彼らの多くは、メーリングリストやStack Overflowのようなウェブサイト、またはRStudio communityを通じて、 。 こうした広範なユーザー・コミュニティは、 、バイオインフォマティクスのような専門分野にも広がっている。 Rコミュニティのそのようなサブセットの1つが、Bioconductorである。“現在および将来の生物学的アッセイからのデータの”分析と理解のための科学的プロジェクトである。 このワークショップは、Bioconductor コミュニティのメンバーによって開発されました。Bioconductor についての詳細は、関連ワークショップ “The Bioconductor Project” をご覧ください。
RStudioを使いこなす
まずはRStudioについて学んでみよう。 は R を扱うための統合開発環境(IDE)だ。
RStudio IDE オープンソース製品は、Affero General Public License (AGPL) v3の下でフリーです。 RStudio IDE は、Posit, Inc.の商用ライセンスおよび 優先メールサポートでもご利用いただけます。
RStudio IDE を使ってコードを書き、 コンピュータ上のファイルを操作し、これから作成する変数を検査し、 生成するプロットを視覚化する。 RStudioは他にも (例:バージョン管理、パッケージの開発、Shynyアプリの作成)にも使えます。 ワークショップでは取り上げません。
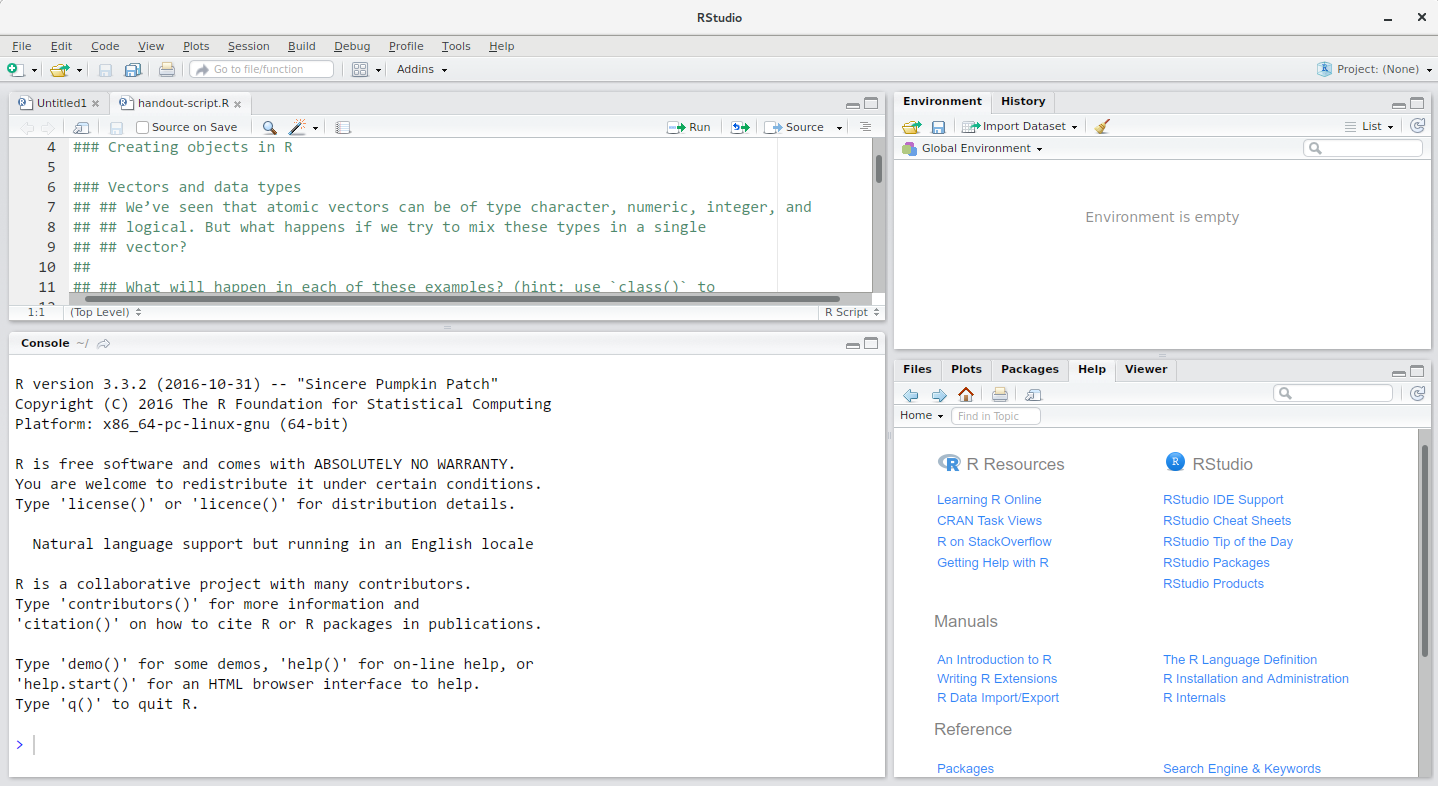
RStudio ウィンドウは 4 つの「ペイン」に分かれています:
- スクリプトとドキュメントの ソース ( のデフォルトレイアウトでは左上)
- あなたの環境/歴史(右上)、
- あなたのFiles/Plots/Packages/Help/Viewer(右下)、そして
- R コンソール(左下)。
これらのペインの配置とその内容はカスタマイズすることができます(
メニューの Tools -> Global Options -> Pane Layout
を参照してください)。
RStudioを使う利点の1つは、コードを書くために必要なすべての情報( )が1つのウィンドウで利用できることです。 さらに、 多くのショートカット、オートコンプリート、およびRでの開発中に使用する主な ファイルタイプのハイライトにより、RStudioは の入力を容易にし、エラーを少なくします。
セットアップ
関連するデータ、分析、テキスト( )のセットは、working directoryと呼ばれる1つのフォルダに自己完結させておくのがよい習慣である。 このフォルダー内のすべてのスクリプトは、 相対パス を使用して、 ファイルがプロジェクト内のどこにあるかを示すことができます( ファイルが特定のコンピューター上のどこにあるかを示す絶対パスとは異なります)。 この方法で作業することで、 、自分のコンピュータ上でプロジェクトを移動したり、 他の人と共有したりすることが、基盤となるスクリプト がまだ動くかどうかを心配することなく、とても簡単になる。
RStudioは、“Projects” インターフェイスを通じて、このような作業を行うための便利なツールセットを提供しています。このツールは、作業ディレクトリを作成するだけでなく、 その場所を記憶し(すぐに移動できるようになります)、 カスタム設定や開いているファイルを保存して、 休憩後に作業を再開しやすくすることもできます。 この チュートリアルのための “Rプロジェクト”の作成手順を以下に示す。
- RStudioを起動します。
- File
メニューの下にあるNew projectをクリックする。 新規ディレクトリを選択し、新規プロジェクトを選択する。 - この新しいフォルダ(または「ディレクトリ」)の名前を入力し、
便利な場所を選択します。 これはこのセッション (またはコース全体) の
作業ディレクトリ になります (例
bioc-intro)。 - Create project`をクリックする。
- (オプション)RStudio でワークスペースを保存しない設定にします。
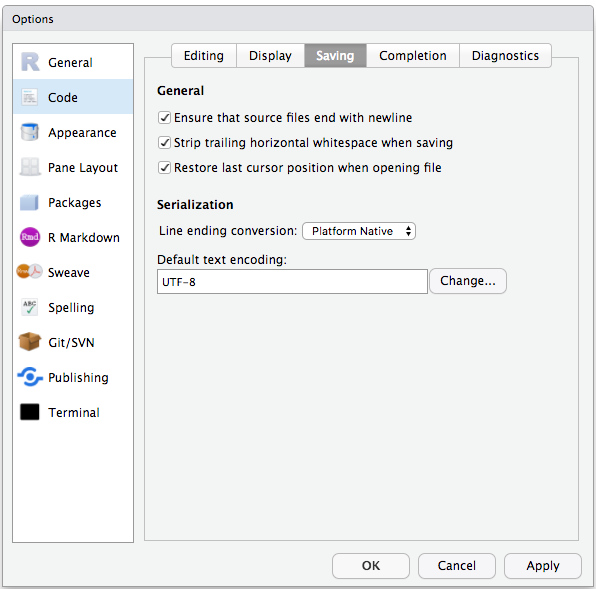
RStudioのデフォルトの環境設定は一般的にうまく機能しますが、ワークスペースを .RDataに保存するのは、特に大きなデータセットを扱う場合は面倒です。 これをオフにするには、「ツール」→「グローバル・オプション」で、終了時に「ワークスペースを.RDataに保存する」 「決してしない」オプションを選択します。

ウィンドウズと他のオペレーティング・システム間の文字エンコーディングの問題](https://yihui.name/en/2018/11/biggest-regret-knitr/)を避けるため、 、デフォルトでUTF-8を設定します:
作業ディレクトリの整理
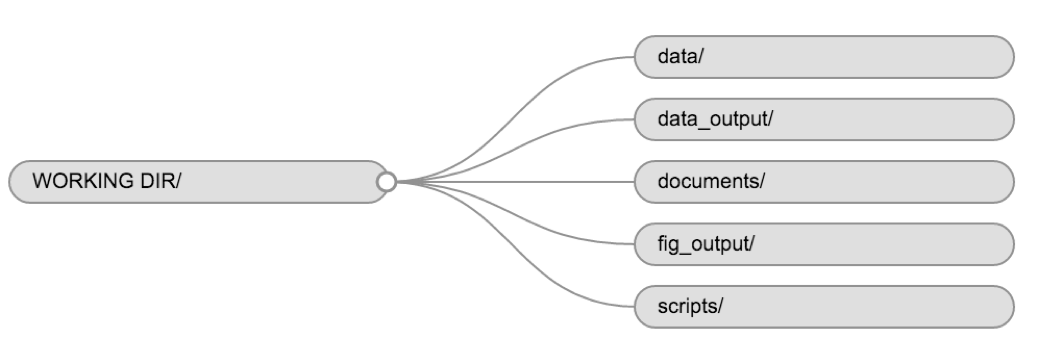
プロジェクト全体で一貫性のあるフォルダ構造を使うことで、 、整理整頓がしやすくなり、将来的に探し出したりファイルしたりするのも簡単になります。 この 、複数のプロジェクトを抱えているときには特に役立つ。 一般的に、 、*スクリプト、*データ、*ドキュメント用のディレクトリ(フォルダ)を作成することができます。
-
data/*
このフォルダは、生データと、特定の分析に必要な中間データセット(
)を保存するために使用します。 透明性と 出所のために、
常に 生データのコピーにアクセスできるようにしておき、
データのクリーンアップと前処理をできるだけプログラム的に(つまり、手作業ではなく
スクリプトで)行うべきである。 生データ
、加工データから切り離すのも良いアイデアだ。 例えば、
data/raw/tree_survey.plot1.txtと...plot2.txtのファイルを、scripts/01.preprocess.tree_survey.Rスクリプトによって生成されたdata/processed/tree.survey.csvファイルとは別に 。 -
documents/ここは、アウトライン、下書き、 、その他のテキストを保管する場所になります。 - **scripts/
** (またはsrc`) この場所には、さまざまな分析やプロット用の R スクリプトを保存し、 関数用の別フォルダを作成することもできます(詳しくは後述します)。
あなたのプロジェクトの必要性に応じて、追加のディレクトリやサブディレクトリが必要になるかもしれないが、これらはあなたの作業用 ディレクトリのバックボーンを形成するはずである。
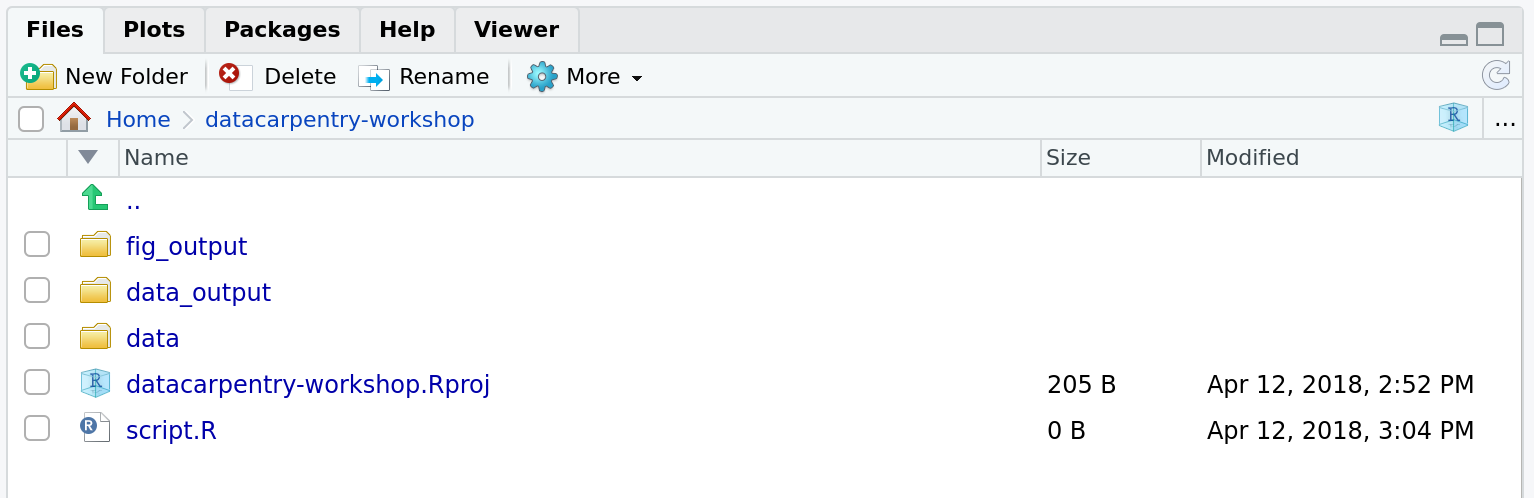
このコースでは、生データを保存するために data/
フォルダが必要です。 、データを CSV
ファイルとしてエクスポートする方法を学ぶために data_output/
フォルダを使用し、図を保存するために fig_output/
フォルダを使用します。
スクリプトは作業ディレクトリのルート に置くことにする。使用するのは1つのファイルだけだし、 事が簡単になるからだ。
作業ディレクトリはこのようになっているはずだ:
プロジェクト管理は、バイオインフォマティクス・プロジェクトにも適用できる。 3。 William Noble (@Noble:2009)は、 以下のディレクトリ構造を提案している:
ディレクトリ名は大きな書体で、ファイル名は小さな 。 ここに掲載したのは、その一部である。 なお、 の日付は、
- - というフォーマットになっているので、 時系列順に並べ替えることができる。 ソースコードsrc/ms-analysis.cがコンパイルされてbin/ms-analysisが作成され、doc/ms-analysis.htmlに文書化されている。 データ・ディレクトリ にあるREADMEファイルには、誰がどの URL から の日付にデータ・ファイルをダウンロードしたかが明記されている。 ドライバスクリプトresults/2009-01-15/runallは自動的に 3つのサブディレクトリ split1、split2、split3 を生成する。 は3つのクロスバリデーション分割に対応する。bin/parse-sqt.pyスクリプトはrunall` ドライバ スクリプトの両方から呼び出される。
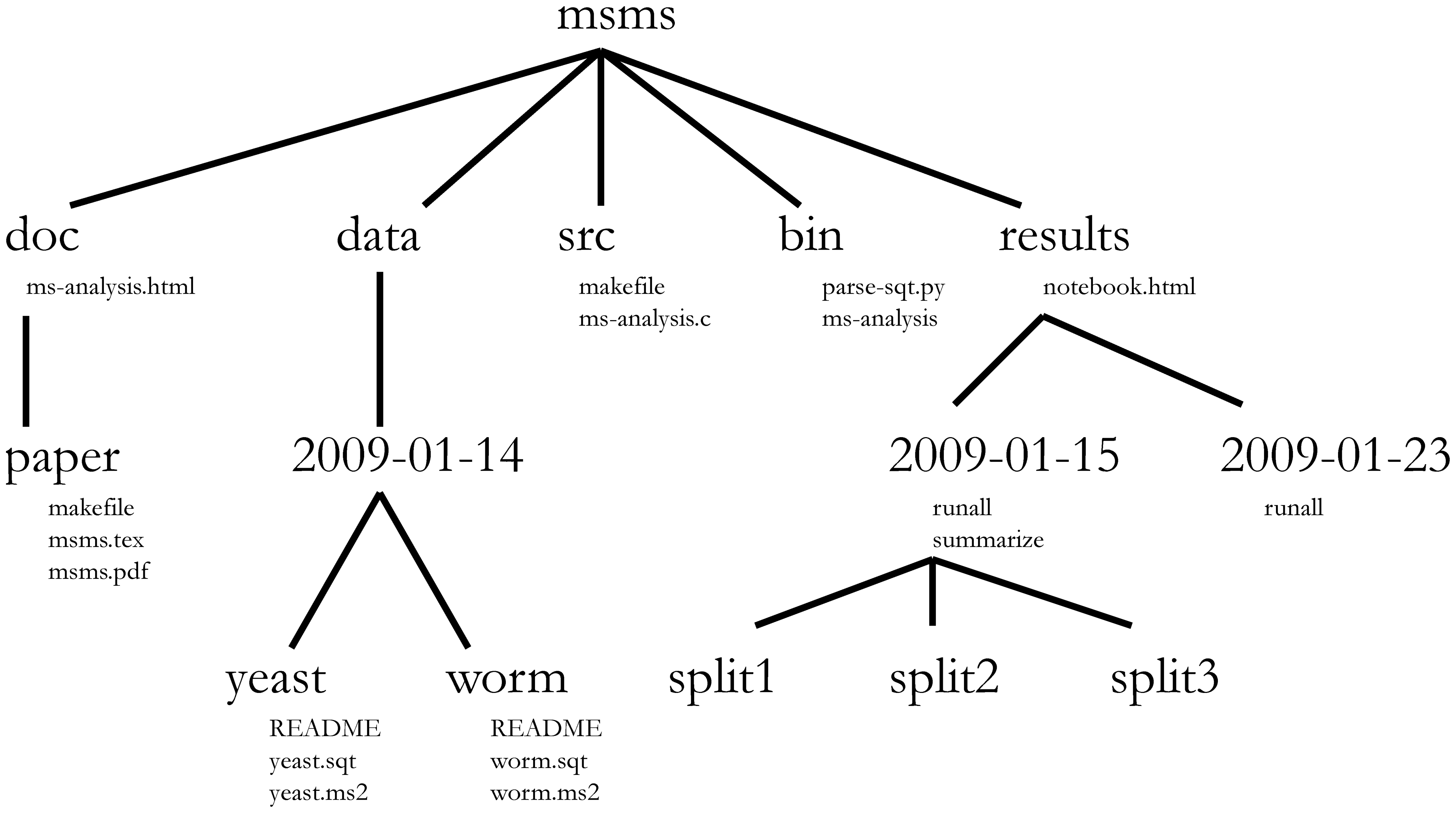
よく定義され、よく文書化された プロジェクトのディレクトリの最も重要な側面は、 プロジェクト4をよく知らない人が、次のことをできるようにすることである。
どのようなプロジェクトなのか、どのようなデータが入手可能なのか、どのような 分析が行われ、どのような結果が出たのかを理解すること、そして最も重要なことは、 を理解することである。
新しいデータで、あるいは 分析パラメーターの一部を変更して、分析を繰り返す。
作業ディレクトリ
作業ディレクトリは理解すべき重要な概念である。 Rがファイルを探して保存する 。 プロジェクトのコードを書くときは、作業ディレクトリのルート に関連するファイルを参照し、この 構造内のファイルだけが必要です。
RStudioプロジェクトを使用すると、この作業が簡単になり、
ディレクトリが適切に設定されます。 もし確認する必要があれば、
getwd() を使うことができる。
何らかの理由で作業ディレクトリが のようになっていない場合は、RStudio
のインターフェイスで
ファイルブラウザーで作業ディレクトリがあるべき場所に移動し、
青い歯車のアイコン More
をクリックし、Set As Working Directory
を選択して変更することができます。
あるいは、setwd("/path/to/working/directory")を使って、
作業ディレクトリをリセットすることもできる。
しかし、あなたのスクリプトには、
、この行を含めるべきではありません。なぜなら、他の誰かのコンピューターで失敗してしまうからです。
**例
以下のスキーマは作業ディレクトリ bioc-intro と
data と fig_output
のサブディレクトリ、そして後者にある2つのファイルを表しています:
bioc-intro/data/
/fig_output/fig1.pdf
/fig_output/fig2.pngもし作業ディレクトリにいれば、相対パス
bioc-intro/fig_output/fig1.pdf か、 絶対パス
/home/user/bioc-intro/fig_output/fig1.pdf を使って
fig1.pdf ファイルを参照することができます。
もし data ディレクトリにいたとしたら、相対パス
../fig_output/fig1.pdf か、同じ絶対パス
/home/user/bioc-intro/fig_output/fig1.pdf
を使うことになる。
Rとの対話
プログラミングの基本は、私たちが 、コンピュータが従うべき命令を書き記し、その 命令に従うようコンピュータに指示することである。 私たちがRで命令を書く、つまり_コード_を書くのは、それが 、コンピューターも私たちも理解できる共通言語だからだ。 私たちは を_コマンド_と呼び、それらのコマンドを_実行_(_実行_とも呼ぶ)することによって、 の指示に従うようにコンピュータに指示する。
Rと対話する主な方法は2つある:
コンソールを使う方法と、スクリプト(
あなたのコードを含むプレーンテキストファイル)を使う方法である。
コンソールペイン(RStudioでは左下のパネル)は、
、R言語で書かれたコマンドを入力し、
、コンピュータによって即座に実行される場所です。 また、
、実行されたコマンドの結果が表示される場所でもある。 コンソールに直接
コマンドを入力し、Enterを押すことで、それらの
コマンドを実行することができますが、セッションを閉じると忘れてしまいます。
コードとワークフローを再現できるようにしたいので、 、スクリプトエディターで必要なコマンドを入力し、 スクリプトを保存する方がよい。 こうすることで、私たちがしたことの完全な記録が残る。 、誰にでも(未来の自分も含めて!)。 は、 の結果を自分のコンピューターで簡単に再現できる。 ただし、スクリプトに 、単にコマンドを入力しただけでは自動的に_実行_されないことに注意してほしい。 、コンソールに送信して実行させる必要がある。
RStudio ではスクリプトエディター から Ctrl +
Enter ショートカット(Mac では Cmd +
Return で も可)で直接コマンドを実行できます。
Ctrl+Enter`を押すと、スクリプトの現在の行のコマンド(カーソルで
を示す)、または現在選択されているテキスト
のすべてのコマンドがコンソールに送られ、実行される。
その他のキーボードショートカットはRStudio cheatsheet about RStudio
IDEを参照してください。
分析のある時点で、
変数の内容やオブジェクトの構造をチェックしたくなるかもしれない。必ずしもスクリプトに
の記録を残しておく必要はない。
これらのコマンドを入力し、コンソールで直接 。 RStudio には
Ctrl + 1 と Ctrl + 2
のショートカットがあり、スクリプトと
のコンソールペイン間をジャンプすることができます。
Rがコマンドを受け付ける準備ができたら、Rコンソールに
> プロンプトが表示される。
コマンドを受信すると(タイプ、コピーペースト、またはスクリプト
エディターから Ctrl + Enter を使って送信)、R
はそれを実行しようとします。 準備ができると、結果を表示し、
新しいコマンドを待つために新しい >
プロンプトで戻ってきます。
Rがまだ
、データの入力を待っている場合は、コンソールに+プロンプトが表示されます。
これは、 、完全なコマンドの入力が終わっていないことを意味する。 これは、
、括弧や引用符を「閉じて」いないからです。つまり、
、左括弧と右括弧の数や、 、開閉引用符の数が同じではないからです。
このようなことが起こり、
、コマンドを入力し終わったと思った場合、コンソール
ウィンドウ内をクリックし、Escを押してください。これにより、不完全なコマンドがキャンセルされ、
>プロンプトに戻ります。
コース中やコース終了後にさらに学ぶには?
このコースで扱う内容は、あなた自身の 研究のためにデータを分析するために R をどのように使うことができるかを、 初めに体験していただくものです。 しかし、データセットのクリーニング、統計的手法の使用、 、美しいグラフィックスの作成5など、 の高度な操作を行うには、さらに学ぶ必要がある。 Rに習熟し、効率的に使えるようになるための最良の方法は、他のツールと同様、Rを使って 実際の研究課題に取り組むことである。 初心者の場合、ゼロからスクリプトを書かなければならないのは、 困難に感じるかもしれない。 多くの人が自分のコードをオンラインで公開していることを考えると、 自分の目的に合うように既存のコードを修正することで、簡単に始めることができるかもしれない。

助けを求める
RStudio 組み込みのヘルプインターフェイスを使用して、R 関数の詳細情報を検索します。
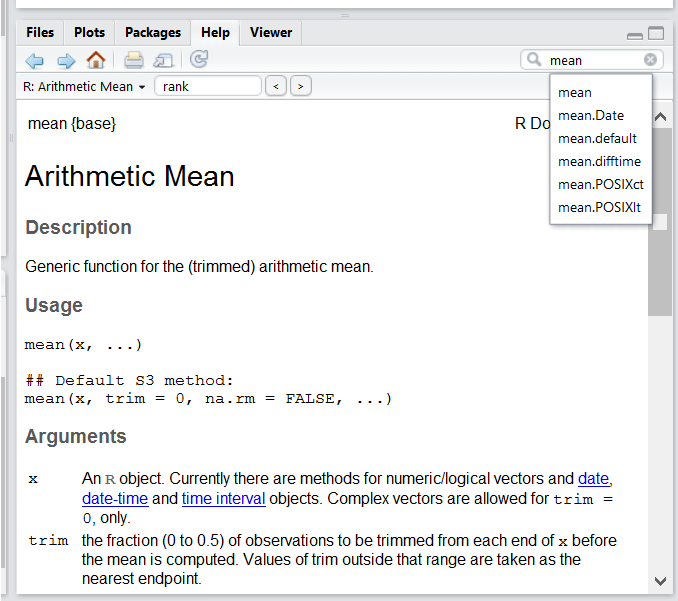
RStudio ヘルプ インターフェイスを使用するのが、ヘルプを得る最も早い方法の1つです。 このパネルはデフォルトで RStudio の右下 パネルにあります。 スクリーンショットに見られるように、 “Mean”という単語を入力すると、RStudioは 、あなたが興味を持ちそうな候補もいくつか出そうとする。 説明文は ウィンドウに表示される。
使いたい関数の名前はわかっているが、その使い方がわからない。
特定の関数、例えばbarplot()のヘルプが必要な場合は、
:
R
バープロット
引数の名前を思い出す必要がある場合は、次のようにすればよい:
R
引数(lm)
Xを行う関数を使いたい。そのための関数があるはずだが、どれがあるのかわからない…。
特定のタスクを実行する関数を探している場合は、
help.search()関数を使用することができます。この関数は二重の疑問符
`?
しかし、これはインストールされているパッケージの中から、検索リクエストと
一致するヘルプページを探すだけです。
R
クルスカル
探しているものが見つからない場合は、 rdocumentation.orgのウェブサイトを使うことができます。このウェブサイトは、利用可能なすべてのパッケージのヘルプファイルから を検索します。
最後に、一般的なグーグルやインターネット検索で “R <task>” を検索すると、多くの場合、 適切なパッケージ・ドキュメントにたどり着くか、 他の誰かがすでに質問している有益なフォーラムにたどり着く。
動けないんだ…。 理解できないエラーメッセージが表示されます。
エラーメッセージをググることから始めよう。 というのも、多くの場合、パッケージ開発者はRが提供するエラー・キャッチに依存しているからである。 、一般的なエラー・メッセージが表示されることになるが、これは の問題を診断するのにあまり役に立たないかもしれない(例えば、“subscript out of bounds”)。 メッセージが非常に一般的なものであれば、 、使用している関数やパッケージの名前を クエリに含めることもできる。
しかし、Stack Overflowをチェックする必要がある。 r]`タグを使って検索する。 ほとんどの の質問にはすでに答えが出されているが、 の答えを見つけるために、検索で適切な の言葉を使うことが課題である:
http://stackoverflow.com/questions/tagged/r
R言語入門](https://cran.r-project.org/doc/manuals/R-intro.pdf) も、プログラミング経験の少ない人にとっては内容が濃いかもしれないが、R言語の基礎を理解するには良い 場所である。
R FAQ](https://cran.r-project.org/doc/FAQ/R-FAQ.html)は密度が濃く、技術的である。 、しかし有用な情報が満載である。
助けを求める
誰かに助けてもらうために重要なのは、相手があなたの問題( )を素早く把握することだ。 、どこに問題がありそうかをできるだけ簡単に特定できるようにすべきだ。
あなたの問題を説明するために、正しい言葉を使うようにしてください。 例えば、 パッケージはライブラリとは違う。 ほとんどの人は、 、あなたが言いたかったことを理解するだろうが、意味の違いについて本当に強い感情を持つ人もいる 。 重要なのは、 、あなたを助けようとする人々を混乱させる可能性があるということだ。 できるだけ正確に問題を説明してください。
可能であれば、うまくいかないことを単純な例(再現可能な )にまで落とし込むようにする。 もし、あなたが50000行10000列のデータではなく、非常に小さなデータ フレームを使って問題を再現できるのであれば、 その小さなデータを問題の説明とともに提供してください。 適切な場合には、 、あなたのやっていることを一般化して、 分野に関係のない人でも質問を理解できるようにする。 例えば、 実際のデータセットのサブセットを使う代わりに、 小さな(3列、5行)一般的なものを作成する。 再現可能な 例の書き方については、Hadley Wickhamによるこの記事を参照のこと。
オブジェクトを他の人と共有するには、それが比較的小さければ、 、関数
dput() を使うことができる。
、メモリ上のオブジェクトとまったく同じオブジェクトを再作成するために使用できるRコードが出力される:
R
## irisはRに付属するデータフレームの例であり、 head()はデータフレームの最初の部分を返す
## 関数である
dput(head(iris))
出力
structure(list(Sepal.Length = c(5.1, 4.9, 4.7, 4.6, 5, 5.4),
Sepal.Width = c(3.5, 3, 3.2, 3.1, 3.6, 3.9), Petal.Length = c(1.4,
1.4, 1.3, 1.5, 1.4, 1.7), Petal.Width = c(0.2, 0.2, 0.2,
0.2, 0.2, 0.4), Species = structure(c(1L, 1L, 1L, 1L, 1L,
1L), levels = c("setosa", "versicolor", "virginica"), class = "factor")), row.names = c(NA,
6L), class = "data.frame")オブジェクトのサイズが大きい場合は、生ファイル(つまり、CSV ファイル)と、エラーが発生した時点までのスクリプト(およびの問題に関係ないものをすべて削除した後のファイル)を提供してください。 あるいは、特にあなたの質問が データフレームに関連していない場合は、任意のRオブジェクトをファイルに保存することができます[^export]:
R
saveRDS(iris, file="/tmp/iris.rds")
しかし、このファイルの内容は人間が読めるものではないので、 Stack
Overflowに直接投稿することはできません。 その代わりに、
。その人はreadRDS()コマンドでそのファイルを読むことができます(ここでは、
、ダウンロードされたファイルは
、そのユーザーのホームディレクトリのDownloadsフォルダにあると仮定しています):
R
some_data <- readRDS(file="~/Downloads/iris.rds")
最後になりますが、必ずsessionInfo()
の出力を含めるようにしてください。プラットフォーム、使用しているRと
パッケージのバージョン、その他問題を理解するのに非常に役立つ情報を提供してくれるからです。
R
sessionInfo()
出力
R version 4.4.1 (2024-06-14)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 22.04.4 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.10.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.10.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
time zone: Asia/Tokyo
tzcode source: system (glibc)
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] compiler_4.4.1 tools_4.4.1 highr_0.11 knitr_1.48
[5] xfun_0.47 evaluate_0.24.0どこに助けを求めればいいのか?
- コース中、あなたの隣に座っている人。 、ワークショップ中に隣の人と話し、自分の答えを比較し、 、助けを求めることをためらわないでください。
- 友好的な同僚:もしあなたより経験豊富な人を知っていれば、 、あなたを助けてくれるかもしれない。
- Stack Overflow: あなたの質問が過去に回答されたことがなく、よく練られたものであれば、 5分以内に回答が得られる可能性があります。 How to ask good questionのガイドラインに従うことを忘れずに。
- R-helpメーリングリスト ](https://stat.ethz.ch/mailman/listinfo/r-help): 多くの人に読まれていて(Rコアチームのほとんどを含む)、多くの人が 投稿していますが、口調はかなり辛口で、 新しいユーザーを必ずしも歓迎しているとは限りません。 あなたの質問が正当なものであれば、 、すぐに回答が返ってくる可能性が高いが、 、スマイルマーク付きで返ってくるとは思わないこと。 また、ここでは他のどこよりも、 正しい語彙を使うようにしましょう(そうしないと、 の質問に答えるのではなく、 あなたの言葉の誤用を指摘する答えが返ってくるかもしれません)。 また、質問内容が特定のパッケージではなく、 ベースとなる関数に関するものであれば、より成功しやすいでしょう。
- 質問が特定のパッケージに関するものであれば、そのパッケージのメーリングリスト(
)があるかどうか確認してください。 通常は
packageDescription("name-of-package")を使ってアクセスできるパッケージのDESCRIPTIONファイル に含まれています。 また、 そのパッケージの作者に直接メールを送ってみたり、 コードリポジトリ(例:GitHub)にissueを開いてみるのもよいだろう。 - また、トピックに特化したメーリングリスト(GIS、 系統遺伝学など)もある。全リストは こちら。
その他のリソース
Rメーリングリストの投稿ガイド。
How to ask for R help 役立つガイドライン。
Jon Skeetによるこのブログ記事 プログラミングの質問の仕方について、かなり包括的なアドバイスがある。
reprex](https://cran.rstudio.com/web/packages/reprex/)パッケージ は、 ヘルプを求めるときに、再現可能な例を作成するのに非常に役立ちます。 rOpenSciコミュニティコール “How to ask questions so they get answered” (Github link and video recording) には、 reprexパッケージとその哲学のプレゼンテーションが含まれています。
Rパッケージ
荷物の積み込み
上で見てきたように、RパッケージはRの基本的な役割を担っている。
、パッケージがインストールされていることを前提に、パッケージの機能を利用する。
、それを利用できるようにするには、まずパッケージをロードする必要がある。
これは library()関数で行う。 以下に ggplot2
をロードする。
R
library("ggplot2")
パッケージのインストール
デフォルトのパッケージリポジトリは The Comprehensive R Archive
Network (CRAN) で、CRAN で利用可能なパッケージは
install.packages() 関数で インストールできます。 例えば、
、後で説明する dplyr パッケージをインストールする。
R
install.packages("dplyr")
このコマンドは、dplyr パッケージと、その
依存パッケージ、つまり、そのパッケージが機能するために依存しているすべてのパッケージをインストールします。
もう一つの主要なRパッケージのリポジトリは、Bioconductorによって管理されている。
Bioconductorパッケージ
は、専用のパッケージ、 すなわち BiocManager
を使用して管理およびインストールされます。
R
install.packages("BiocManager")
SummarizedExperiment(後で )、DESeq2(RNA-Seq解析用)、その他BioconductorやCRANにあるパッケージは、BiocManager::install`で
。
R
BiocManager::install("SummarizedExperiment")
BiocManager::install("DESeq2")
デフォルトでは、BiocManager::install()
はインストールされているすべてのパッケージをチェックし、新しいバージョンがあるかどうかも確認します。
もしあれば、それが表示され、「すべて/いくつか/なしを更新しますか?
[a/s/n]:`、そしてあなたの答えを待つ。
パッケージのバージョンは最新のものを用意するよう努力すべきですが、実際には、パッケージがロードされる前の新鮮なRセッションでのみパッケージを更新することをお勧めします。
コマンドライン コンソールから直接Rを使うのとは対照的だ。 、Rとインターフェイスし統合するソフトウェアは他にもあるが、RStudioは非常に高度な機能を数多く備えながら、特に初心者向け 。↩︎
すなわち、バイオインフォマティクスのデータ解析など、Rに新しい機能を付与するアドオンである。 。↩︎
このコースでは、バイオインフォマティクスを、 、生物学的または生物医学的データに適用されるデータサイエンスと考える。↩︎
その誰かとは、 、分析が実行された数カ月後、あるいは数年後に、 、未来のあなた自身である可能性が高い。↩︎
ここでは、これらのほとんど(統計学を除く) を紹介するが、Rで可能なこと の富の表面をかすめることしかできない。↩︎