スプレッドシートを使用したデータ整理
最終更新日:2024-09-08 | ページの編集
概要
質問
- 表形式のデータを整理するにはどうすればよいですか?
目的
- スプレッドシートとその長所と短所について学びます。
- データを効果的に使用するには、スプレッドシート内のデータをどのようにフォーマットすればよいでしょうか?
- 一般的なスプレッドシートのエラーとその修正方法について説明します。
- きちんとしたデータの原則に従ってデータを整理します。
- カンマ区切り (CSV) 形式やタブ区切り (TSV) 形式などのテキストベースのスプレッドシート形式について説明します。
This episode is based on the Data Carpentries’s Data Analysis and Visualisation in R for Ecologists lesson.
表計算プログラム
質問
- 優れたデータ統合用にスプレッドシートを使用するための基本的な原則は何でしょうか?
客観的
- コンピューターがデータセットを に活用できるようにデータを整理するためのベスト プラクティスについて説明します。
キーポイント
- 適切なデータ構成は、あらゆる研究プロジェクトの基礎です。
適切なデータ構成は、研究 の基礎です。 ほとんどの研究者はデータを持っているか、 シートにデータ入力を行っていません。 スプレッドシート プログラムは、データ テーブルを設計し、非常に基本的 データ品質管理機能を処理するための非常に便利な インターフェイスです。 @Broman:2018 も参照してください。
スプレッドシートの概要
スプレッドシートはデータ入力に適しています。 したがって、スプレッドシートにはデータ がたくさんあります。 研究者としての時間の多くは、この「データの検討」段階 費やされることになります。 とても楽しいわけではありませんが、必要性は です。 データの編成について考える方法と、より効果的なデータ ラングリングのための かの実践方法を説明します。
このレッスンで教えられないこと
- スプレッドシートで 統計 を行う方法
- スプレッドシートで プロット を行う方法
- スプレッドシート プログラムで _コードを記述する_方法
これを実行したい場合は、O 発行の Head First Excel 参考になります。 「ライリー。
なぜスプレッドシートでのデータ分析を教えないのか
スプレッドシートでのデータ分析には通常、多くの 作業が必要です。 パラメーターを変更したり、 データセットを使用して分析を実行したりする場合は、通常、すべてを手動でやり直す必要があります。 (マクロを作成できることはわかりませ が、次の点を参照してください。)
また、 の作業に戻りたいときや、誰かが分析の詳細を尋ねたときに、スプレッドシート プログラムで行われた統計分析やプロット分析を追跡したり再現したりすること 困難です。
多くの表計算プログラムが利用可能です。 ほとんどの参加者は主なスプレッドシート プログラムとして を使用するため、このレッスンで Excel の例を使用します。 で使用できる表計算プログラムは LibreOffice です。 コマンドはプログラム間 少し異なる場合がありますが、一般的な考え方は同じです。
スプレッドシート プログラムには、研究者としてできる にする必要のある多くのことが含まれています。 それらは次の目的で使用できます。
- データ入力
- データの整理
- データのサブセット化と並べ替え
- 統計
- プロット
スプレッドシート プログラムはテーブルを使用してデータを表し、表示します。 テーブルとしてフォーマットされたデータ この章の主要テーマであり、効率的なダウンストリーム分析を にするために、標準化された方法でデータをテーブルに編成する方法 見ていきます。
スプレッドシートの問題
スプレッドシートはデータ入力には適していますが、実際にはデータ入力以外の目的で シート プログラムを使用する傾向があります。 これら を使用して、出版物のデータ テーブルを作成し、概要 統計を生成し、図を作成します。
スプレッドシートでパブリケーション用のテーブルを生成することは ではありません。多くの場合、パブリケーション用にデータ テーブルをフォーマットするとき、実際にはデータとして読み取ら ことを意図していない方法で重要な概要統計をレポートすることに 、特殊なフォーマットが必要になることがよくあります。 (セルを結合し、境界線を作成し、美しくする)。 この種の操作は文書編集ソフトウェア内で行う をお勧めします。
統計と数値を生成する後者の 2 つのアプリケーションは、 して使用する必要があります。1 スプレッド プログラムのグラフィカルなドラッグ アンド ドロップの性質のため、 手順を複製するのが不可能ではないにしても、非常に困難になる可能性があります (元に戻すことはさらに困難です)。特に の統計や数値により、より複雑な計算が必要な場合はそうです。 さらに、スプレッドシートで計算を行う場合、 わずかに異なる数式を の隣接するセルに誤って適用してしまうことがよくあります。 R や SAS などのコマンドライン ベースの統計プログラムを使用する場合、意図的に実行しない限り、データセット内の観測値には計算を適用し、別の観測値には計算を適用しないことは事実上不可能です。
スプレッドシートでのデータテーブルの書式設定
質問
- データを効果的に使用するには、スプレッドシート内のデータをどのようにフォーマットすればよいでしょうか?
目的
シートでのデータ入力と書式設定のベスト プラクティスについて説明します。
ベスト プラクティスを適用して、変数と観測値を シートに配置します。
キーポイント
生データは決して変更しないでください。 を加える前に必ずコピーを作成してください。
データをクリーンアップするために実行したすべての手順を テキスト ファイルに記録します。
きちんとしたデータの原則に従ってデータを整理します。
最もよくある間違いは、スプレッドシート プログラムを研究室の ブックのように扱うことです。つまり、情報を伝えるためにコンテキスト、余白のメモ、データとフィールドの空間 レイアウトに依存していることです。 人間として、これらのことを (通常は) 解釈できますが、コンピューターは情報 同じようには見ません。そして、すべての の意味をコンピューターに説明しない限り (それ 難しい場合があります!)、理解できません。 データがどのように組み合わされるかを確認できます。
コンピューターの力を利用すると、 効果的かつ高速な方法でデータを管理および分析できますが、その力を使用するには、コンピューターが理解できるようにデータを する必要があります ( コンピューターは非常に複雑です)。リテラル)。
このため、 の予備実験からデータの入力を開始する前に、適切にフォーマットされた をセットアップすることが非常に重要です。 データの整理は研究プロジェクトの です。 分析全体を通じて の操作が容易になるか困難になる可能性があるため、データ入力を行う や実験を設定するときに考慮する価値があります。 スプレッドシートではさまざまな方法で設定できますが、これらの 選択の一部によっては、 のプログラムでデータを操作する能力が制限されたり、6 か月後の自分や共同作業者が共同作業したりすることが制限される可能性があります。 データ。
注: データ入力とデータ分析に最適なレイアウト/形式 (およびソフトウェアと ) は異なる場合があります。 これを考慮し、理想的にはあるものから のものへの変換を自動化することが です。
分析を追跡する
スプレッドシートを使用しているとき、データのクリーンアップ 分析を行っているときに、最初のスプレッドシートとは 異なる外観のスプレッドシートが完成することがよくあります。 分析を したり、査読者や講師が別の分析を要求したときに何をしたかを把握したりするには、次のこと 行う必要があります。
クリーンアップまたは分析されたデータを含む新しいファイルを作成します。 元のデータセット 変更しないでください。変更すると、どこから始めたのかわからなくなります。
クリーンアップまたは分析で実行した手順を記録します。 実験の他のステップと同様に、これらのステップを追跡する必要があり 。 データ ファイルと同じフォルダーに保存された テキスト ファイルでこれを行うことをお勧め ます。
これはスプレッドシート設定の例です。
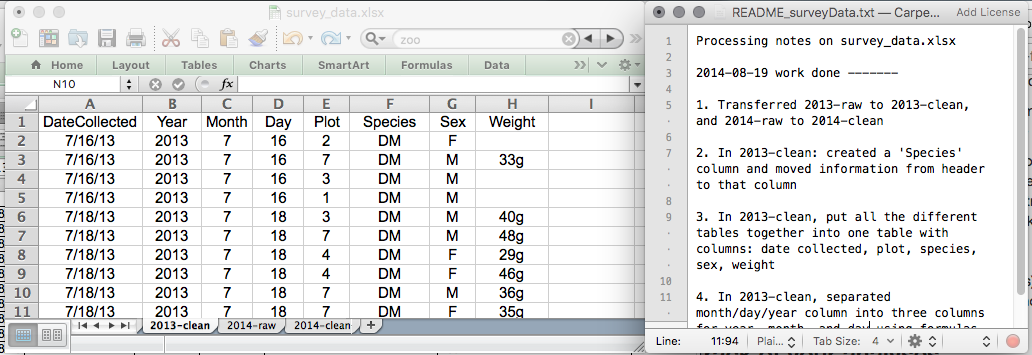
今日の演習中にこれらの原則を実践してください。
バージョン管理はこのコースの範囲外ですが、バージョンを維持 方法については、 ‘Git’ の Carpentries レッスンを参照してください。データを制御します。 簡単なチュートリアルについてはこの ブログ 投稿 を、より研究指向のユースケースについては @Perez-Riverol:2016 も参照してください。
スプレッドシートでのデータの構造化
データにスプレッドシート プログラムを使用する際の基本ルールは次のとおりです。
- すべての変数を列に入力します。測定対象は「重量」や「温度」 です。
- 各観測値を独自の行に配置します。
- 1 つのセルに複数の情報を組み合わせないでください。 場合によっては それは単なる つのことのように思えますが、それがそのデータを使用または並べ替えできるようにする唯一の方法であるかどうかを考えてください。
- 生データはそのままにしておきます。変更しないでください。
- クリーンアップされたデータを CSV (カンマ区切り値) 形式などのテキストベースの形式にエクスポートします。 これにより、誰でも を使用できるようになり、ほとんどのデータ リポジトリで必要になります。
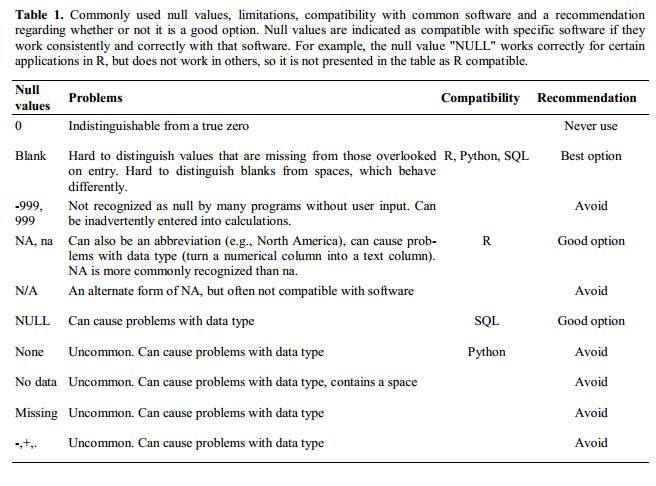
たとえば、ベルギーのブリュッセルにあるいくつか 病院を訪れた患者からのデータがあります。 彼らは、訪問日、 、患者の性別、体重、血液型を記録しました。
次のようにデータを追跡するとします。
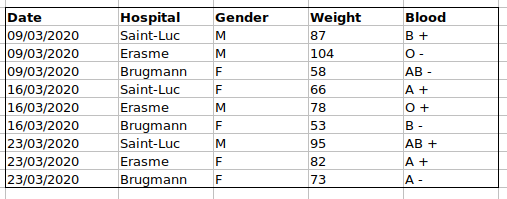
問題は、ABO グループと Rhesus グループが同じ「Blood」 タイプ列にあることです。 したがって、A グループのすべての観測値を調べたり、ABO グループごとの重み分布を調べたりしたい場合、このデータ設定を使用してこれを行うのは難しいでしょう 。 代わりに、ABO グループと Rhesus グループを別の列に配置すると、はるかに簡単になることがわかります。
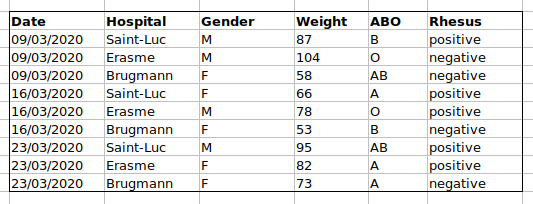
データシートを設定する際の重要なルールは、列は変数に され、行は観測に使用されるということです。
- 列は変数です
- 行は観測結果です
- セルは個別の値です
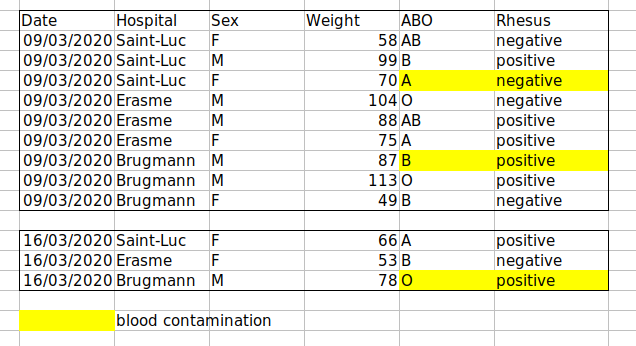
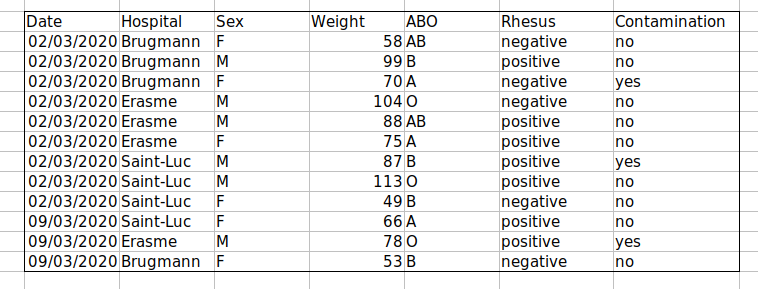
課題: 乱雑なデータセットを取り上げ、それをクリーンアップする方法を説明します。
ここ をクリックして、乱雑なデータセットをダウンロードします。
スプレッドシート プログラムでデータを開きます。
タブが 2 つあることがわかります。 このデータには、2020 年の新型コロナウイルス感染症 (COVID-19) の第 波と第 2 波の間にブリュッセルのさまざまな病院で記録されたさまざま 臨床変数が含まれています。 ご覧のとおり、 データは 3 月と 11 月 の波では異なる方法で記録されています。 あなたはこのプロジェクトの責任者となり、 データの分析を開始できるようにしたいと考えています。
隣にいる人と一緒に、この スプレッドシートのどこが間違っているのかを特定してください。 また、最初と 2 番目の Wave タブをクリーンアップし、それらをすべて つのスプレッドシートにまとめるために必要な手順について 説明します。
重要: 最初のアドバイスを忘れないでください。クリーンアップされたデータ用に ファイル (またはタブ) を作成する場合は、元の (生の) データを決して変更しないでください。
この演習を終えた後、このデータの が間違っていたのか、そしてそれをどのように修正するのかをグループで話し合います。
特に R スクリプト に関する 優れた参考文献は、Tidy Data 論文 @Wickham:2014 です。
よくあるスプレッドシートのエラー
質問
- スプレッドシート のデータの書式設定に関する一般的な課題は何ですか?また、それらを回避するにはどうすればよいですか?
目的
- 一般的なスプレッドシートの書式設定の問題を認識して解決します。
キーポイント
- 1 つのスプレッドシート内で複数のテーブルを使用しないでください。
- データが複数のタブに分散しないようにします。
- ゼロはゼロとして記録します。
- 欠落データを記録するには、適切な null 値を使用します。
- 情報を伝えたり、スプレッドシートを美しく見せるために書式設定を使用しないでください。
- コメントは別の列に配置します。
- 列ヘッダーに単位を記録します。
- セルには 1 つの情報のみを含めます。
- 列ヘッダーにはスペース、数字、特殊文字を使用しないでください。
- データ内では特殊文字を避けてください。
- メタデータを別のプレーン テキスト ファイルに記録します。
自分自身のデータ でなく、共同作業者やインターネットからのデータにも、注意すべき潜在的なエラーがいくつかあります。 エラーや、下流 データ分析 結果の解釈に悪影響が及ぶ可能性があることを認識 ていれば、自分やプロジェクト メンバーがエラーを回避しようとする動機になるかもしれません。 スプレッドシートでデータをフォーマットする方法に 変更を加えると、データのクリーニング と分析の効率と信頼性に大きな影響 を与える可能性があります。
- 複数のテーブルの使用
- 複数のタブの使用
- ゼロを埋めない
- 問題のある null 値の使用
- 情報を伝えるために書式設定を使用する
- 書式設定を使用してデータシートを美しく見せる
- セル内にコメントまたはユニットを配置する
- セルに複数の情報を入力する
- 問題のあるフィールド名の使用
- データ内での特殊文字の使用
- データテーブルへのメタデータの組み込み
複数のテーブルの使用
一般的な戦略は、1 つ スプレッドシート内に複数のデータ
テーブルを作成することです。
これはコンピュータを混乱させるので、行わないでください。
1
つのスプレッドシート内に複数のテーブルを作成すると、コンピュータにとっては、各行を観測
として認識するため、物事の間に た関連付けが描画されることになります。
また、同じフィールド名を
の場所で使用している可能性があり、データを使用可能な形式に
アップすることが困難になります。 以下の例は問題を示しています。
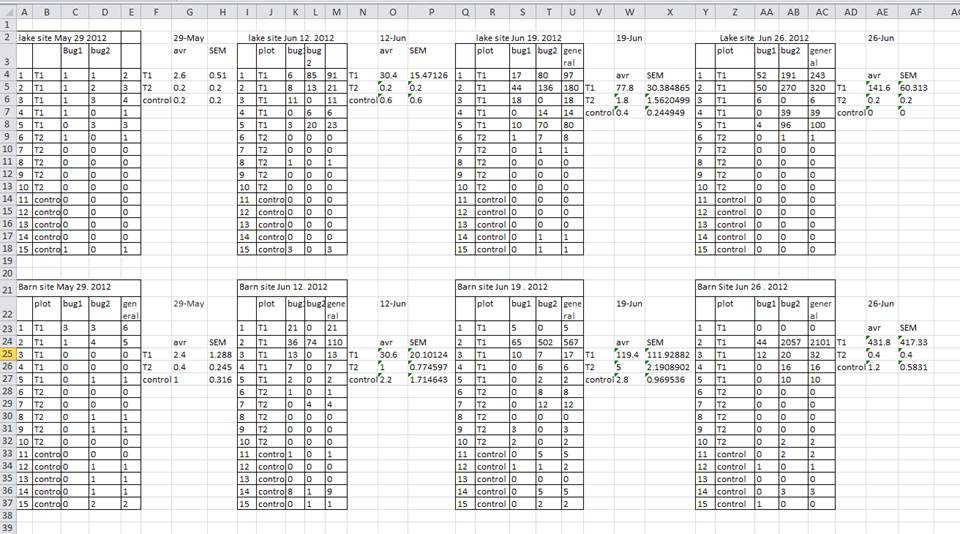
上の例では、コンピュータは、(たとえば) 行 4 と 、すべての列 A ~ A F が同じサンプルを参照しているとみなして表示します。 この行 、実際には 4 つの異なるサンプル (5 月 29 日、6 月 12 日、6 月 19 日、および 6 月 26 日の つの異なる収集日のそれぞれのサンプル 1) と、計算されたいくつかの概要統計 (平均 (avr) およびこれら のサンプルのうち 2 つの標準測定誤差 (SEM))。 他の行にも同様に問題があります。
複数のタブの使用
しかし、ワークブックのタブはどうでしょうか? データを整理する簡単な方法のように思えますよね? まあ、はい、いいえです。 追加のタブを作成すると、そこにあるデータの接続をコンピュータに認識させることができなく ます (この接続を確保するには、 スプレッドシート アプリケーション固有の関数を導入するか、 スクリプトを導入する必要があります)。 たとえば、測定を行う日ごとに のタブを作成するとします。
これは次の 2 つの理由から良い習慣ではありません。
測定を行うたびに新しいタブでデータ の記録を開始すると、誤って データに不一致が追加される可能性が高くなります。
たとえすべての不一致が忍び寄るのを防ぐことができたとしても、 これらのデータを単一 データテーブルに結合する必要があるため、 データを分析する前に余分な手順を追加することになります。 タブ 結合する方法をコンピュータに明示的に指示する必要があります。また、タブの形式が一貫していない場合は、 で結合する必要がある場合もあります。
次回データを入力するときに、別のタブ またはテーブルを作成するときは、元のスプレッドシートに別の列を 追加することで、このタブの追加を回避できるかどうか自問してください。 乱雑なデータ ファイルの では複数のタブを使用しましたが、データを 編成してタブ間で統合する方法がわかりました。
の過程でデータシートが非常に長くなる可能性があります。 これにより、スプレッドシートの上部に ヘッダーが表示されない場合、データの入力が困難になります。 ただし、ヘッダー 行を繰り返さないでください。 これらは簡単にデータに混入し、 的に問題が発生する可能性があります。 代わりに、列 ヘッダーを固定する ことができます。これにより、多くの 行を含むスプレッドシートがある場合でも、それらの行が表示されたままになります。
ゼロを埋めない
何かを測定するとき、調査でウサギが観察された回数は通常 である可能性があります。 その列にはほとんどゼロがあるのに、なぜわざわざ という数字のゼロを書き込むのでしょうか?
ただし、 スプレッドシートのゼロと空白のセルには違いがあります。 コンピューターにとって、ゼロは実際にはデータです。 あなたが測ったか、 なかった。 空白のセルは、測定されていないことを意味し、 はそれを未知の値 (ヌル または欠損値とも呼ばれます) として解釈します。
スプレッドシートや統計プログラムでは、ゼロであるつもりの の空白セルが誤って解釈される可能性があります。 観測値 入力しないことにより、そのデータ を不明または欠落 (null) として表すようにコンピュータに指示することになります。 これにより、後続の の計算または分析で問題が発生する可能性があります。 たとえば、単一の null 値を含む一連の数値 の平均は常に null です ( は欠落している観測値を推測できないため)。 このうち であるため、ゼロをゼロとして記録し、真に 欠損データをヌルとして記録することが非常に重要です。
問題のある null 値 {#null}の使用
例: -999 またはその他の数値 (またはゼロ) を に使用すると、欠損データを表します。
解決策:
データセット内で null 値が異なる で表現される理由はいくつかあります。 紛らわしいヌル値が測定装置から自動的に として記録される場合があります。 その場合、できることは ではありませんが、ツール を使用してデータ クリーニングで対処できます 1 OpenRefine 前分析。 また、データが存在しないさまざまな理由を伝えるために、 な null 値が使用されることもあります。 これは取得すべき重要 情報ですが、実際には 1 つの列を使用して 2 つの情報を取得することになります。 フォーマットを使用して 情報を伝える と同様に、ここでは「data_missing」のような新しい 列を作成し、その列を使用して の異なる理由をキャプチャすると良いでしょう。
理由が何であれ、不明または欠落しているデータが として -999、999、または 0 として記録されている場合は問題です。
多くの統計プログラムは、これらが欠損 (NULL) 値を表す であることを認識しません。 これらの値 がどのように解釈されるかは、データの分析に使用するソフトウェアによって異なります。 明確に定義された一貫性のある null インジケーターを使用することが です。
空白 (ほとんどのアプリケーション) と NA (R の場合) が 選択肢として適しています。 @White:2013 は、記事の中で、さまざまなソフトウェア アプリケーションに対して null 値 を示すための適切な選択肢について説明しています。
フォーマットを使用して情報を伝える
例: 分析から 必要があるセル、行、または列を強調表示し、空白の行を残してデータの 分離を示します。
解決策: 新しいフィールドを作成して、 データをエンコードします。
書式設定を使用してデータシートを美しく見せる {#formatting_pretty}
例: セルを結合します。
解決策: 注意しないと、ワークシートを より美しく見えるように書式設定すると、データ内の 関連付けを認識するコンピュータの機能が損なわれる可能性があります。 セルを結合すると、統計ソフトウェアで を読み取ることができなくなります。 データを整理する にセルを結合する必要がないような方法でデータを再構築することを検討してください。
セル {#units}にコメントまたはユニットを配置する
ほとんどの分析ソフトウェアは Excel や LibreOffice のコメントを表示できないため、 データ セル内に配置されたコメントによって混乱する可能性があります。 書式設定について で説明したように、セルに を追加する必要がある場合は、別のフィールドを作成します。 同様に、セルに単位を含めないでください。理想的には、1 つの列に配置する の測定値が同じ 単位内にある必要がありますが、何らかの理由でそうでない場合は、別のフィールドを作成し、 セルの単位を指定します。で。
セル {#info}に複数の情報を入力する
例: A+、 B+、A- などの ABO グループとアカゲザル グループを 1 つのセルに記録する
解決策: セルに複数の情報を含めないでください。
これにより、データを分析できる方法が制限されます。
の場合、これらの測定値の両方が必要な場合は、
この情報を含めるようにデータシートを設計します。 たとえば、ABO
グループには 1 つの列を含め、Rhesus グループには つの列を含めます。
問題のあるフィールド名 {#field_name} の使用
説明的なフィールド名を選択しますが、スペース、 数字、またはいかなる種類の特殊文字も含めないように注意してください。 スペースは、空白を区切り文字として使用するパーサーによって て解釈される可能性があり、一部の プログラムは 数字で始まるテキスト文字列であるフィールド名を好みません。
アンダースコア (_) はスペースの代わりに使用できます。
読みやすさを向上させるために、
名前をキャメルケースで記述することを検討してください (例:
ExampleFileName)。 現時点では意味のある略語 も、6
か月後にはそれほど明確ではなくなる可能性があることに注意してください。ただし、
が長すぎる名前を付けすぎないでください。 フィールド名に
を含めることで混乱が回避され、他の人がフィールドを簡単に解釈できるようになります。
例
| いい名前 | 良い代替品 | 避ける |
|---|---|---|
| 最高_温度_C | 最大温度 | 最高温度 (°C) |
| 降水量_mm | 降水量 | プレcmm |
| 平均_年_成長 | 平均年成長 | 平均成長率/年 |
| sex | セックス | 男/女 |
| weight | 重さ | w。 |
| セル_タイプ | セルタイプ | 細胞の種類 |
| 観察_01 | 最初の_観察 | 1回目の観測 |
データ {#special}での特殊文字の使用
例: たとえば、Word または のアプリケーションからデータを直接コピーするなど、メモを書くときにスプレッドシート プログラムをワード プロセッサ として扱います。
解決策: これは一般的な戦略です。 たとえば、セルに の長いテキストを書き込む場合、スプレッドシートに改行、全角ダッシュ、 などを含めることがよくあります。 また、Word など アプリケーションからデータをコピーする場合、書式設定や派手な 標準文字 (左揃えと右揃えの引用符など) が含まれます。 このデータをコーディング/ 環境またはリレーショナル データベースにエクスポートすると、行が半分に切断されたり、エンコード エラーが発生したりする 、危険なことが発生する可能性があります。
一般的なベスト プラクティスは、改行、 タブ、垂直タブなどの文字の追加を避けることです。 言い換えれば、テキスト セルを、テキストとスペースのみを含めることができる単純な Web フォームで かのように扱います。
データテーブル {#metadata}へのメタデータの組み込み
例: データ テーブル の上部または下部に、列の意味、単位、例外などを説明する凡例を追加します。
解決策: データに関するデータ (「メタデータ」) を記録することは ではありません。 データセットを して分析している間は、データセットと親密な関係にあるかもしれませんが、変数「sglmemgp」がグループの単一のメンバー (たとえば を意味すること、または以前に使用した正確なアルゴリズムを意味することをまだ覚えている可能性は ありません。変数 変換するか、派生変数を作成すると、数か月後、1 年後、またはそれ以上かかります。
また、他の人があなたのデータを調べたり、使用したりする理由はたくさんあります。あなたの発見を理解するため、 を検証するため、 提出された出版物をレビューするため、結果を再現するため、 同様の研究を計画するため、さらには他の人がアクセスしたり 利用できるようにデータをアーカイブします。 デジタルデータは定義上、 可読ではありませんが、その意味を理解することは の仕事です。 研究の収集段階および分析段階でデータを文書化することの重要性は、特に研究が 記録の一部となる場合には 過大評価することはできません 。
ただし、データファイル 自体にはメタデータを含めないでください。 論文や補足ファイルの表とは異なり、メタデータ ( 形式) はデータ ファイルに含めるべきではありません。この情報はデータではなく、 データを含めるとコンピューター プログラムがデータ ファイルを解釈する が混乱する可能性があるためです。 むしろ、メタデータは、データ ファイルと同じディレクトリに別のファイルとして保存する必要があります。できればファイルと明確に関連付けられる名前を付けてプレーン テキスト形式で保存する必要があります。 メタデータ ファイルはフリー テキスト形式であるため、コメント、単位、 値のエンコード方法に関する情報などをエンコードすることも ます。これらの情報は文書化するには重要ですが、データ ファイルの 設定を混乱させる可能性があります。
さらに、ファイルまたはデータベース レベルのメタデータは、データセットを構成するファイルが相互に ように関連するかを記述します。どのような形式であるか。 は、以前のファイルに優先されるか、または以前のファイルによって置き換えられるか。 フォルダー レベルの readme.txt ファイルは、プロジェクト内のすべて ファイルとフォルダーを説明する古典的な方法です。
(メタデータに関するテキストは、EDINA および 大学データ ライブラリによるオンライン コース Research Data MANTRA から改変されました。 MANTRA は クリエイティブ コモンズ 表示 4.0 国際 ライセンス に基づいてライセンスされています。
データのエクスポート
質問
- ストリーム アプリケーションに役立つ方法でスプレッドシートからデータをエクスポートするにはどうすればよいでしょうか?
目的
- スプレッドシート データをユニバーサル ファイル形式で保存します。
- スプレッドシートから CSV ファイルにデータをエクスポートします。
キーポイント
一般的なスプレッドシート形式で保存されたデータは、データ分析ソフトウェアに 読み込まれないことが多く、 にエラーが生じます。
スプレッドシートから CSV や TSV などの形式にデータをエクスポートすると、ほとんどのプログラムで一貫して使用できる形式でデータが になります。
分析に使用するデータを Excel 既定のファイル形式 (Excel
バージョンに応じて *.xls または *.xlsx)
で保存することはお勧めできません。 なぜ?
これは独自の形式であり、 的にはファイルを開くことが不可能では にしても不便になる技術が存在しなくなる (または十分にまれになる) 可能性があるためです。
他の表計算ソフトウェアでは、 の Excel 形式で保存されたファイルを開くことができない場合があります。
Excel のバージョンが異なるとデータの処理方法が異なる場合があり、 整合が発生する可能性があります。 日付 は、データ ストレージにおける不整合の十分に文書化された例です。
最後に、データをデータ リポジトリに することを要求するジャーナルや補助金機関が増えています。また、そのほとんどは Excel 形式を受け入れ ん。 で説明する形式のいずれかである必要があります。
上記の点は、LibreOffice / Open Office で使用されるオープン データ 形式などの他の形式にも当てはまります。 これらの形式は ではなく、 ソフトウェア パッケージによって同じ方法で解析されません。
データを汎用的でオープンな静的形式で保存すると、この問題に するのに役立ちます。 タブ区切り (タブ区切り値または TSV) または カンマ区切り (カンマ区切り値または CSV) を試してください。 CSV ファイルは、列がカンマで区切られたプレーン テキスト ファイルです。したがって、「カンマ で区切られた値」または CSV と呼ばれます。 Excel/SPSS/などと した CSV ファイルの利点ファイルは、TextEdit や などのプレーン テキスト エディタを含む、ほぼすべてのソフトウェア を使用して CSV ファイルを開いて読み取ることができるということです。 CSV ファイル内のデータは、SQLite や R などの他 形式や環境にも簡単にインポートできます。CSV ファイルを使用する場合、特定の高価なプログラムの のバージョンに縛られることがないので、最大限の移植性と 性を実現するために使用するフォーマット。 ほとんどのスプレッドシート プログラムは などの区切りテキスト形式で簡単に保存できますが、ファイルのエクスポート に警告が表示される場合があります。
Excel で開いたファイルを CSV 形式で保存するには:
- 上部のメニューから「ファイル」と「名前を付けて保存」を選択します。
- [形式] フィールドのリストから、[カンマ区切りの 値]
(
*.csv) を選択します。 - ファイル名と する場所を再確認し、「保存」をクリックします。
下位互換性に関する重要な注意: ファイルは Excel で開くことができます。
エラー
Error in loadNamespace(x): there is no package called 'Knitr'R と xls に関するメモ: xls
ファイル (および Google スプレッドシート) を読み取ることができる R
パッケージがあります。 「xls」ドキュメント内の
ワークシートにアクセスすることも可能です。
しかし
- これらの中には Windows でのみ動作するものもあります。
- これは、データ分析 R コードの追加の複雑さ/依存性を
して、(単純だが手動の)
csvへのエクスポートを置き換えることに相当します。 - データ形式のベスト プラクティスは引き続き適用されます。
-
csv(または類似のもの) が では不十分である正当な理由は本当にあるのでしょうか?
カンマに関する注意事項
一部のデータセットでは、データ値自体にカンマ (,) が含まれる場合があります。 その場合、使用しているソフトウェア (Excel を含む) により、列内のデータが誤って表示される可能性が ます。 これは、データ値の一部であるカンマの が 区切り文字として解釈されるためです。
たとえば、データは次のようになります。
種 ID、属、種、分類群
AB、Amphispiza、bilineata、鳥類
AH、Ammospermophilus、harrisi、げっ歯類、国勢調査されていない
AS、Ammodramus、savannarum、鳥類
BA、Baiomys、taylori、げっ歯類レコード「AH,Ammospermophilus,harrisi,Rodent, not censused」では、「taxa」の値 コンマが含まれています (「Rodent, not censused」)。 上記を Excel (または他のスプレッドシート プログラム) に読み込むために を試みると、 のような結果が得られます。
エラー
Error in loadNamespace(x): there is no package called 'Knitr'taxa の値は (1 つの列 D に
を入れる代わりに) 2 つの列に分割されました。 これはさらに多数の
エラーに伝播する可能性があります。
たとえば、追加の列は、欠損値が多数ある (適切なヘッダーがない) 列
として解釈されます。 に加えて、行 3 のレコードの列 D の値
(つまり、‘taxa’ の値にカンマが含まれている の値)
も正しくなくなりました。
データを「csv」形式で保存し、 データ値にカンマが含まれる可能性があることが予想される場合は、値を引用符 (““) で囲むことで、上記 で説明した問題を回避できます。 このルールを適用すると、 データは次のようになります。
種 ID、属、種、分類群
"AB"、"Amphispiza"、"bilineata"、"Bird"
"AH"、"Ammospermophilus"、"harrisi"、"げっ歯類、国勢調査されていない"
"AS"、"Ammodramus" 、"サバンナルム"、"鳥"
"BA"、"バイオミス"、"テイロリ"、"げっ歯類"Excel では 引用符の外側にあるカンマのみが区切り文字として使用されるため、このファイルを Excel で「csv」として開いても、余分な 列は生成されません。
あるいは、カンマを含むデータを操作している場合、 シートで作業するときに別の区切り文字を使用する必要がある可能 があります1。 この場合、区切り文字としてタブを使用し、TSV ファイルを扱う場合は 使用することを検討してください。 TSV ファイルは、CSV ファイルと同じ方法でスプレッドシート プログラムからエクスポートできます。
データ の値が “” に含まれていないものの、区切り文字 とデータ値の一部としてカンマが含まれている既存のデータセットを操作している場合は、データ クリーニングに関する重大な問題 に直面する可能性があります。 扱っているデータセットに 百または数千のレコードが含まれている場合、それらを手動でクリーンアップする ( データ値からカンマを削除するか、値を 引用符 (““) で囲む) と、何時間もかかるだけではありません。ただし、誤って のエラーが発生する可能性があります。
データセットのクリーンアップは、多くの 分野における主要な問題の 1 つです。 このアプローチは、ほとんどの場合、特定 コンテキストに依存します。 ただし、スクリプトを作成して実行するなど、 化された方法でデータをクリーンアップすることをお勧めします。 Python と R のレッスンは、 するスクリプトを構築するためのスキルを開発するための基礎を提供します。
まとめ

典型的なデータ分析ワークフローは、上の図 に示されており、データは繰り返し変換、視覚化、モデル化されます。 この の繰り返しは、データが理解されるまで複数回繰り返されます。 ただし、 の実際のケースでは、実際にデータを分析して理解すること ではなく、データのクリーンアップと準備 にほとんどの時間が費やされます。
変換/視覚化/モデルのサイクルを高速で 回繰り返すアジャイルなデータ分析ワークフローは、データが予測可能な方法で されており、データを調べたり したりすることなく推論できる場合にのみ実現可能です。それ。
これは、カンマが小数点の として使用されるヨーロッパの 諸国に特に関係します。 このような場合、 csv ファイルのデフォルト値の区切り文字はセミコロン (;) になるか、値は体系的に引用符で囲まれた になります。↩︎