Quartoを用いた再現可能なレポート
最終更新日:2025-04-15 | ページの編集
所要時間: 12分
概要
質問
- 再現可能なレポートをどのように作成できますか?
目的
-
targetsを使用してレポートを生成できるようになる
エピソードの概要: Quartoを使用したレポートの書き方を紹介
コピー&ペースト vs. 動的ドキュメント
通常、データ分析の結果をより広いオーディエンスに伝えたいと考えるでしょう。
以前は、統計、プロット、その他の結果をテキストドキュメントやプレゼンテーションにコピー&ペーストすることでこれを行っていたかもしれません。 これは、分析を一度だけ行う場合には問題ありません。 しかし、それはほとんどの場合ではありません。分析の一部を調整したり、新しいデータを追加してパイプラインを再実行する可能性がはるかに高いです。 コピー&ペーストの方法では、どの結果が変更されたかを覚えておき、手動ですべてが最新であることを確認しなければなりません。 これは危険な作業です!
幸いにも、targets
はドキュメントをパイプラインの結果と同期させるための関数を提供しており、このような落とし穴を避けることができます。
ドキュメントを生成するために使用する主なツールは Quarto
です。 Quarto は targets
とは別に使用することもできます(これは独自に大きなトピックですが)、targets
と組み合わせて動的にレポートを生成する優れた方法でもあります。
Quarto を使用すると、Rコードの結果をドキュメントに直接挿入できるため、コピー&ペーストのミスの危険がありません。 さらに、PDF、HTML、Microsoft Word など、同じ基礎となるスクリプトから複数の形式で出力を生成することができます。
Quartoのインストール
v2022.07.1以降、RStudioにはQuartoが含まれていますので、別途インストールする必要はありません。RStudioからQuartoを実行できない場合は、最新バージョンのRStudioをインストールすることをお勧めします。
Quartoファイルについて
.qmd または .Qmd
はQuartoファイルの拡張子で、「Quarto markdown」の略です。
Quartoファイルは、コードとコメントの通常の書き方を逆転させています。典型的なRスクリプトでは、すべてのテキストはコメントでない限りRコードと見なされますが、Quartoではすべてのテキストが散文と見なされ、評価されるRコードの行を示すために特別な表記を使用します。
コードが評価されると、その結果が最終的なレンダリングされたドキュメントに挿入され、さまざまな形式の一つになる可能性があります。
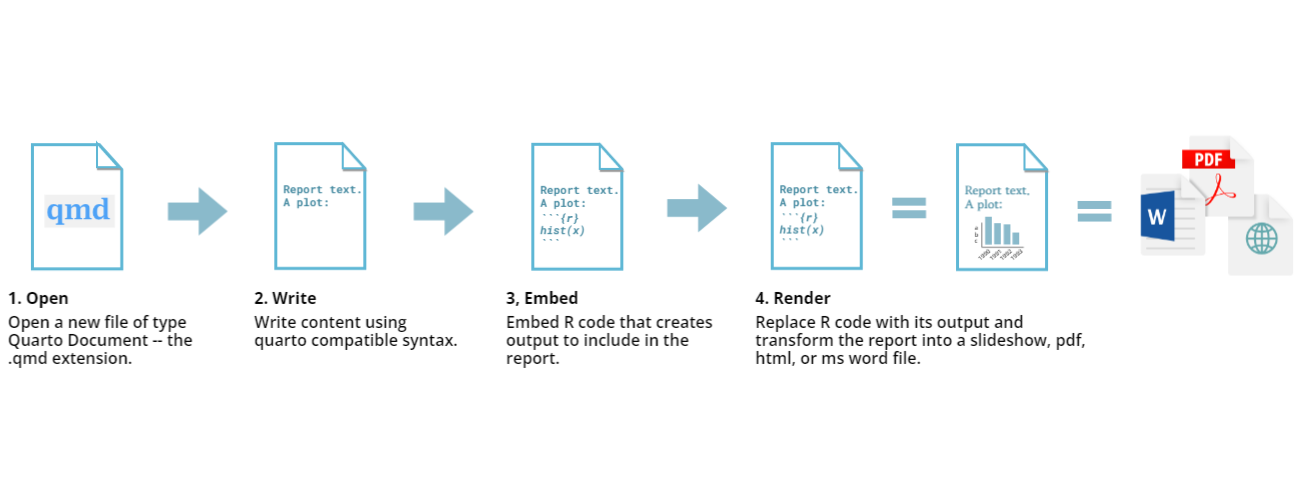
このレッスンではQuartoの詳細に踏み込む時間がありませんが、このトピックについては “RStudioによる再現可能な出版物のイントロダクション” インキュベーター(開発中)のレッスン をお勧めします。
推奨ワークフロー
Quartoのような動的ドキュメント(またはQuartoの前身であるRmarkdown)は、実際にはデータ分析パイプラインの管理に使用できます。
しかし、これはスケーラビリティが低く、targets
が提供する高度な依存関係追跡が欠けているため、推奨されません。
私たちの推奨アプローチは、データ分析の大部分(つまり「重い作業」)を
targets
パイプラインで実行し、Quartoドキュメントを使用して結果を
要約 し、 プロット することです。
ペンギンのくちばしの大きさに関するレポート
ペンギンのくちばしの大きさの分析を続けて、各モデルを評価するレポートを書きましょう。
時間を節約するために、レポートはすでに https://github.com/joelnitta/penguins-targets にあります。
こちらから生のコードをコピーして、新しいファイル
penguin_report.qmd
としてプロジェクトフォルダに保存してください(ブラウザで右クリックして「名前を付けて保存」を選択することもできます)。
次に、tar_quarto()
関数を使用してパイプラインにもう一つターゲットを追加します。以下のようにします:
R
source("R/functions.R")
source("R/packages.R")
tar_plan(
# Load raw data
tar_file_read(
penguins_data_raw,
path_to_file("penguins_raw.csv"),
read_csv(!!.x, show_col_types = FALSE)
),
# Clean data
penguins_data = clean_penguin_data(penguins_data_raw),
# Build models
models = list(
combined_model = lm(
bill_depth_mm ~ bill_length_mm, data = penguins_data),
species_model = lm(
bill_depth_mm ~ bill_length_mm + species, data = penguins_data),
interaction_model = lm(
bill_depth_mm ~ bill_length_mm * species, data = penguins_data)
),
# Get model summaries
tar_target(
model_summaries,
glance_with_mod_name(models),
pattern = map(models)
),
# Get model predictions
tar_target(
model_predictions,
augment_with_mod_name(models),
pattern = map(models)
),
# Generate report
tar_quarto(
penguin_report,
path = "penguin_report.qmd",
quiet = FALSE,
packages = c("targets", "tidyverse")
)
)
レポートを生成する関数は tar_quarto()
で、tarchetypes パッケージから提供されています。
ご覧のとおり、モデルの実行という「重い」分析はワークフロー内で行われ、その後
tar_quarto()
を使用してレポートをレンダリングする一つの呼び出しが最後にあります。
targets
はいつレポートをレンダリングするかをどのように知るのか?
このままでは、targets がワークフローの
最後
にレポートを生成することをどのように知っているのかがすぐには明らかではありません(ビルド順序はターゲットがワークフロー内で書かれた順序ではなく、それらの依存関係によって決まることを思い出してください)。
penguin_report
は他のターゲットに依存していないように見えます。なぜなら、それらは
tar_quarto() の呼び出しに表示されていないからです。
これはどのように機能するのでしょうか?
答えは penguin_report.qmd ファイルの
内部
にあります。ファイルの開始部分を見てみましょう:
MARKDOWN
---
title: "Simpson's Paradox in Palmer Penguins"
format:
html:
toc: true
execute:
echo: false
---
```{r}
#| label: load
#| message: false
targets::tar_load(penguin_models_augmented)
targets::tar_load(penguin_models_summary)
library(tidyverse)
```
これは南極のパルマー諸島におけるペンギンの分析の一例です。最初の --- と ---
の間の行は「YAMLヘッダー」と呼ばれ、ドキュメントをレンダリングする方法に関する指示が含まれています。
実行されるRコードは ```{r} と ```
の間の行で指定されます。これは「コードチャンク」と呼ばれ、散文テキストに挿入されたコードの一部です。
Rコードチャンクを詳しく見てみましょう。
targets::tar_load()
の2つの呼び出しに注目してください。この関数が何をするか覚えていますか?これはワークフロー中にビルドされたターゲットをロードします。
これで少し理解が深まったはずです。targets
はレポートがワークフロー中にビルドされたターゲット、penguin_models_augmented
および penguin_models_summary に依存していることを
レポート内で tar_load()
を使用してロードしているため 知っています。
動的コンテンツの生成
penguin_report.qmd の開始部分での
tar_load()
の呼び出しは、最新のレポートを生成するための鍵です。これらがワークフローからロードされると、データと同期していることがわかり、それらを使用して「洗練された」テキストやプロットを生成することができます。
チャレンジ: 動的コンテンツを見つけよう
penguin_report.qmd
を読み、ワークフロー中にビルドされたターゲット
(penguin_models_augmented および
penguin_models_summary)
がテキストやプロットを動的に生成するために使用されている箇所を見つけてみてください。
results-statsとラベル付けされたコードチャンクでは、P-値や調整済み R 二乗値などのモデルからの統計が抽出され、`r mod_stats$combined$r.squared`のようなインラインコードを使用してテキストに挿入されています。2つの図があります。一つは結合モデル用、もう一つは別々のモデル用です(それぞれ
fig-combined-plotとfig-separate-plotとラベル付けされたコードチャンク)。これらはpenguin_models_augmentedのモデルから予測されたポイントを使用して構築されています。
penguin_report.qmd
のコードを対話的に実行して、tar_load()
から何が起こっているのかをよりよく理解するべきです。実際、このレポートはそのように書かれました。コードが対話セッションで実行され、望ましい結果を得るために徐々に調整されながらレポートに保存されました。
このレポート生成アプローチを学ぶ最良の方法は、自分で試すこと です。
したがって、最終的なチャレンジは、自分のデータを使用して
targets
ワークフローを構築し、レポートを生成することです。頑張ってください!
まとめ
-
tarchetypes::tar_quarto()は Quarto ドキュメントをレンダリングするために使用されます - Quarto ドキュメント内で
tar_load()およびtar_read()を使用してターゲットをロードする必要があります - 重い計算は主な
targetsワークフローで行い、軽いフォーマットやプロットの生成は Quarto ドキュメントで行うことが推奨されます