初めての targets ワークフロー
最終更新日:2025-04-15 | ページの編集
所要時間: 12分
概要
質問
- 分析を整理するためのベストプラクティスは何ですか?
-
_targets.Rファイルは何のためのものですか? -
_targets.Rファイルの内容は何ですか? - ワークフローを実行するにはどうしますか?
目的
- RStudioでプロジェクトを作成する
-
_targets.Rファイルの目的を説明する - 基本的な
_targets.Rファイルを書く -
_targets.Rファイルを使用してワークフローを実行する
エピソードの概要: 非常にシンプルなワークフローを書いて、初めて実際に手を動かしてみる機会
プロジェクトの作成
プロジェクトについて
targets
は分析を整理するために「プロジェクト」の概念を使用します。特定のプロジェクトに必要なすべてのファイルを1つのフォルダ、プロジェクトフォルダにまとめます。
プロジェクトフォルダには、データ、コード、結果用のフォルダなど、整理のための追加のサブフォルダがあります。
プロジェクトを使用することで、他の作業に時間を費やした後に分析に戻った際に、簡単に再び方向付けることができます。
もし一度に1つの作業のみを完了させる場合は問題になりませんが、実際にはほとんどの場合そうではありません。
他の作業をした後にプロジェクトに戻るときに、何をしていたかを覚えておくのは難しいです(「コンテキストスイッチング」と呼ばれる現象)。
標準化された整理システムを使用することで、混乱や時間の浪費を減らすことができます。つまり、再現性を高めることになります!
このワークショップでは、プロジェクトの整理概念ともうまく連携する RStudio を使用します。
RStudioでプロジェクトを作成する
RStudioを使用して新しいプロジェクトを開始しましょう。
「ファイル」をクリックし、「新しいプロジェクト」を選択します。
これにより、新しいプロジェクトウィザードが開き、プロジェクトの設定を手助けする一連のメニューが表示されます。
ウィザードで最初のオプション「新しいディレクトリ」をクリックします。これは、新しいプロジェクトをゼロから作成するためです。
次のメニューで「新しいプロジェクト」をクリックします。
「ディレクトリ名」には、プロジェクトの目的を思い出しやすい名前を入力します。例えば「targets-demo」(ファイルやフォルダの命名のベストプラクティスに従ってください)。
「プロジェクトをサブディレクトリとして作成する…」の下で、「参照」ボタンをクリックしてプロジェクトを配置するディレクトリを選択します。
プロジェクトを簡単に見つけられるように、デスクトップに配置することをお勧めします。
「Gitリポジトリを作成」と「このプロジェクトで renv を使用する」はチェックを外したままにできますが、これらは再現性を向上させる優れたツールです。もしまだであれば、将来的に学習して使用することを検討してください。
これらは後からでも有効にできるため、すぐに使用しようと心配する必要はありません。
これらの手順を進めると、RStudioのセッションは次のようになります:
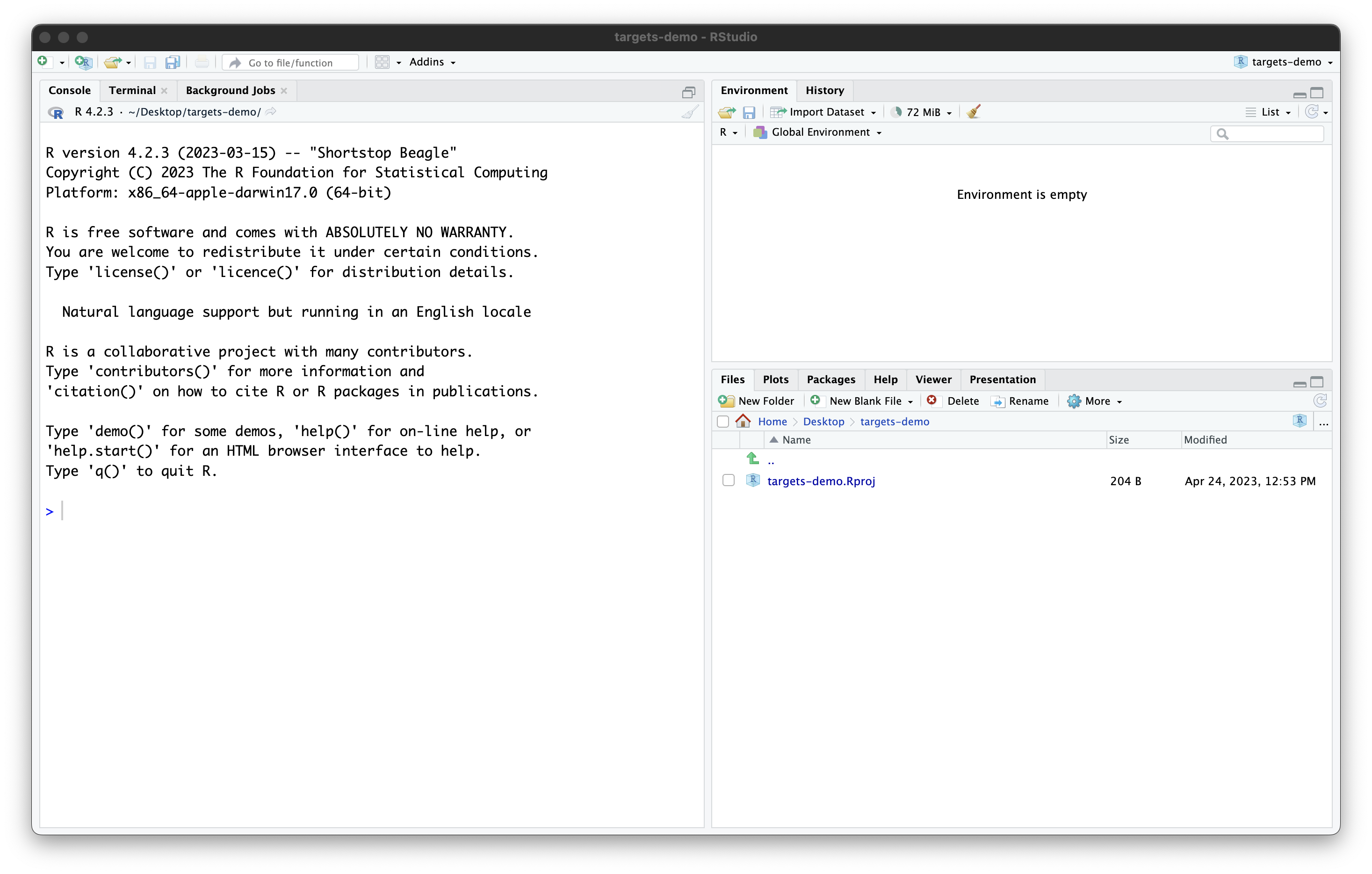
プロジェクトには現在、RStudioによって作成された1つのファイル
targets-demo.Rproj
が含まれています。このファイルを手動で編集しないでください。その目的は、RStudioにこのフォルダがプロジェクトフォルダであることを伝え、いくつかのRStudio設定を保存することです(バージョン管理ソフトウェアを使用している場合は、このファイルをコミットしても構いません)。また、ファイルエクスプローラーで
.Rproj
ファイルをダブルクリックすることでプロジェクトを開くことができます(RStudioを終了してからファイルブラウザでデスクトップに移動し、「targets-demo」フォルダを開いて
targets-demo.Rproj
をダブルクリックして試してください)。
さて、プロジェクトが設定されたので、targets
の使用を開始する準備ができました!
_targets.R ファイルの作成
すべての targets
プロジェクトには、メインプロジェクトフォルダ(「プロジェクトルート」)にある特別なファイル
_targets.R を含める必要があります。
_targets.R
ファイルにはワークフローの仕様が含まれており、Rに分析を実行する指示が記述されています。これはレシピのようなものです。
_targets.R
ファイルを使用することで、特定のスクリプトを特定の順序で実行することを覚えておく必要がなくなります。
代わりに、Rがそれを自動的に実行してくれます(再現性が向上します)!
_targets.R ファイルの構成
これから _targets.R
ファイルの作成を開始します。幸い、targets
にはこれを手助けする関数が用意されています。
Rコンソールで、まず library(targets) で
targets パッケージを読み込み、次に
tar_script() コマンドを実行します。
R
library(targets)
tar_script()
コンソールでは何も起こりませんが、ファイルビューアに新しいファイル
_targets.R
が表示されます。ファイルメニューを使用するか、クリックして開いてください。
このデフォルトの _targets.R
ファイルには3つの主要な部分が含まれています:
-
library()を使用したパッケージの読み込み -
function()を使用したカスタム関数の定義 -
list()を使用したリストの定義
最後の部分であるリストは、_targets.R
ファイルの中で最も重要な部分です。
ワークフローのステップを定義します。
_targets.R
ファイルは常にこのリストで終わらなければなりません。
さらに、リスト内の各項目は tar_target()
関数の呼び出しです。
tar_target()
の最初の引数はビルドするターゲットの名前で、2番目の引数はそれをビルドするために使用するコマンドです。
ターゲットの名前は引用符なし、つまり、引用符で囲まれていないことに注意してください。
例示分析を実行するための _targets.R ファイルの設定
背景: targets を使用しないバージョン
このテンプレートを使用して、ペンギンのくちばしの形状の分析を構築し始めます。
しかしまず、使用する関数やパッケージに慣れるために、targets
を使用せずに「通常の」Rスクリプトでコードを実行してみましょう。
データを取得するために palmerpenguins
Rパッケージを使用していることを思い出してください。
このパッケージには実際にデータセットの2つのバリエーションが含まれています。1つは生データを含む外部CSVファイルで、もう1つはRに読み込まれたクリーンなデータです。
実際のところ、生データは外部に保存されていることが多いため、生のペンギンデータ を分析の出発点として使用しましょう。
palmerpenguins の path_to_file()
関数は、生データCSVファイルへのパスを提供します(これは、パッケージをインストールしたときにコンピュータにダウンロードされた
palmerpenguins
Rパッケージのソースコード内にあります)。
R
library(palmerpenguins)
# Get path to CSV file
penguins_csv_file <- path_to_file("penguins_raw.csv")
penguins_csv_file
出力
[1] "/home/runner/.local/share/renv/cache/v5/linux-ubuntu-jammy/R-4.4/x86_64-pc-linux-gnu/palmerpenguins/0.1.1/6c6861efbc13c1d543749e9c7be4a592/palmerpenguins/extdata/penguins_raw.csv"データの読み込みと操作には、tidyverse
パッケージ群を使用します。
今は tidyverse
の使用方法のすべての詳細をカバーする時間がありませんが、詳細を学びたい場合は、“tidyverse
を使用したデータの操作、分析、およびエクスポート” レッスン
を参照してください。
read_csv() を使用してデータを読み込みましょう。
R
library(tidyverse)
# Read CSV file into R
penguins_data_raw <- read_csv(penguins_csv_file)
penguins_data_raw
出力
Rows: 344 Columns: 17
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (9): studyName, Species, Region, Island, Stage, Individual ID, Clutch C...
dbl (7): Sample Number, Culmen Length (mm), Culmen Depth (mm), Flipper Leng...
date (1): Date Egg
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.出力
# A tibble: 344 × 17
studyName `Sample Number` Species Region Island Stage `Individual ID`
<chr> <dbl> <chr> <chr> <chr> <chr> <chr>
1 PAL0708 1 Adelie Penguin… Anvers Torge… Adul… N1A1
2 PAL0708 2 Adelie Penguin… Anvers Torge… Adul… N1A2
3 PAL0708 3 Adelie Penguin… Anvers Torge… Adul… N2A1
4 PAL0708 4 Adelie Penguin… Anvers Torge… Adul… N2A2
5 PAL0708 5 Adelie Penguin… Anvers Torge… Adul… N3A1
6 PAL0708 6 Adelie Penguin… Anvers Torge… Adul… N3A2
7 PAL0708 7 Adelie Penguin… Anvers Torge… Adul… N4A1
8 PAL0708 8 Adelie Penguin… Anvers Torge… Adul… N4A2
9 PAL0708 9 Adelie Penguin… Anvers Torge… Adul… N5A1
10 PAL0708 10 Adelie Penguin… Anvers Torge… Adul… N5A2
# ℹ 334 more rows
# ℹ 10 more variables: `Clutch Completion` <chr>, `Date Egg` <date>,
# `Culmen Length (mm)` <dbl>, `Culmen Depth (mm)` <dbl>,
# `Flipper Length (mm)` <dbl>, `Body Mass (g)` <dbl>, Sex <chr>,
# `Delta 15 N (o/oo)` <dbl>, `Delta 13 C (o/oo)` <dbl>, Comments <chr>生データにはスペースを含む扱いにくい列名があり(これらはタイプミスしやすくコードのミスにつながりやすい)、必要なものよりもはるかに多くの列があります。
この分析の目的では、種名、くちばしの長さ、くちばしの深さのみが必要です。
生データでは、「culmen」というやや技術的な用語がくちばしを指すために使用されています。

下流の分析で使用しやすくするためにデータを整理しましょう。
後で一部の関数でエラーを引き起こす可能性があるため、欠損データを含む行も削除します。
R
# Clean up raw data
penguins_data <- penguins_data_raw |>
# Rename columns for easier typing and
# subset to only the columns needed for analysis
select(
species = Species,
bill_length_mm = `Culmen Length (mm)`,
bill_depth_mm = `Culmen Depth (mm)`
) |>
# Delete rows with missing data
remove_missing(na.rm = TRUE)
penguins_data
出力
# A tibble: 342 × 3
species bill_length_mm bill_depth_mm
<chr> <dbl> <dbl>
1 Adelie Penguin (Pygoscelis adeliae) 39.1 18.7
2 Adelie Penguin (Pygoscelis adeliae) 39.5 17.4
3 Adelie Penguin (Pygoscelis adeliae) 40.3 18
4 Adelie Penguin (Pygoscelis adeliae) 36.7 19.3
5 Adelie Penguin (Pygoscelis adeliae) 39.3 20.6
6 Adelie Penguin (Pygoscelis adeliae) 38.9 17.8
7 Adelie Penguin (Pygoscelis adeliae) 39.2 19.6
8 Adelie Penguin (Pygoscelis adeliae) 34.1 18.1
9 Adelie Penguin (Pygoscelis adeliae) 42 20.2
10 Adelie Penguin (Pygoscelis adeliae) 37.8 17.1
# ℹ 332 more rowsこれで良くなりました!
targets バージョン
targets を使用するとどのようになりますか?
最大の違いは、ワークフローの各ステップを最後のリストに追加する必要があることです。
データクリーニングステップのためにカスタム関数も定義します。
これは、最後のターゲットのリストが分析の高レベルな要約のように見えるべきだからです。
ターゲットを定義するときに長いコードの塊を避けたいです。代わりに、そのコードをカスタム関数に入れます。
他のステップ(ファイルパスの設定とデータの読み込み)はそれぞれ1つの関数呼び出しだけなので、それらを独自のカスタム関数に入れる意味はあまりありません。
最後に、ワークフローの各ステップは tar_target()
関数で定義されます。
R
library(targets)
library(tidyverse)
library(palmerpenguins)
clean_penguin_data <- function(penguins_data_raw) {
penguins_data_raw |>
select(
species = Species,
bill_length_mm = `Culmen Length (mm)`,
bill_depth_mm = `Culmen Depth (mm)`
) |>
remove_missing(na.rm = TRUE)
}
list(
tar_target(penguins_csv_file, path_to_file("penguins_raw.csv")),
tar_target(penguins_data_raw, read_csv(
penguins_csv_file, show_col_types = FALSE)),
tar_target(penguins_data, clean_penguin_data(penguins_data_raw))
)
read_csv() で show_col_types = FALSE
に設定したのは、先ほどのコードから列の型がデフォルトで正しく設定されている(種には文字列、くちばしの長さと深さには数値)ことがわかっているためです。したがって、通常発生する警告を表示する必要はありません。
ワークフローの実行
ワークフローができたので、tar_make()
関数を使用して実行できます。
それを実行してみてください。次のようなものが表示されるはずです:
R
tar_make()
出力
▶ dispatched target penguins_csv_file
● completed target penguins_csv_file [0.001 seconds]
▶ dispatched target penguins_data_raw
● completed target penguins_data_raw [0.098 seconds]
▶ dispatched target penguins_data
● completed target penguins_data [0.007 seconds]
▶ ended pipeline [0.236 seconds]おめでとうございます、targets
を使って最初のワークフローを実行しました!
まとめ
- プロジェクトは分析を整理しておくのに役立ち、後で簡単に再実行できます
- RStudioのプロジェクトウィザードを使用してプロジェクトを作成する
-
_targets.Rファイルはすべてのtargetsプロジェクトに含める必要がある特別なファイルであり、ワークフローを定義します -
tar_script()を使用してデフォルトの_targets.Rファイルを作成する -
tar_make()を使用してワークフローを実行する